
最近はChatGPTやGeminiなどの生成AIが身近になりました。
しかし、個人的なメモや機密情報を含むデータを、
クラウド上のAIに送信することに抵抗を感じる場面も少なくありません。
また、クラウド型のAIは利用回数に制限があったり、
サブスクリプションのコストがかかったりすることがネックになります。
そこで今回は、自分のパソコン上(ローカル環境)で
大規模言語モデル(LLM)を動かすことができる
無料の実行エンジン「Ollama(オラマ)」を導入してみました。
この記事では、Ollamaの特徴と、Windows環境へのインストール手順、
そして実際にAIモデルを動かすまでの初期設定について、
実際の画面を交えて解説します。
ローカルAI実行エンジン「Ollama」とは
Ollamaは、自分のパソコンの中でAIモデルを動かすためのオープンソースソフトウェアです。実際に使ってみて、以下のような特徴があることがわかりました。
- 完全に無料で利用できる
- インターネットに接続しなくても動作するため、情報漏洩のリスクがない
- 面倒な環境構築が不要で、インストールが非常に簡単
- パソコンに搭載されているグラフィックボード(GPU)を自動認識して処理を高速化する
特に、『アプリ画面から使いたいAIモデルを選んで話しかけるだけで、ダウンロードから実行までを全自動でやってくれる』という手軽さが、Ollamaの最大のメリットだと感じました。
Ollamaのインストール手順(Windows環境)
ここからは、実際にWindowsのパソコンにOllamaをインストールする手順を解説します。
公式サイトからのダウンロード
まずはOllamaの公式サイトにアクセスして、インストーラーをダウンロードします。
- Ollamaの公式サイト(https://ollama.com/)にアクセスします。
- トップページ右上の「Download」ボタンをクリックします。
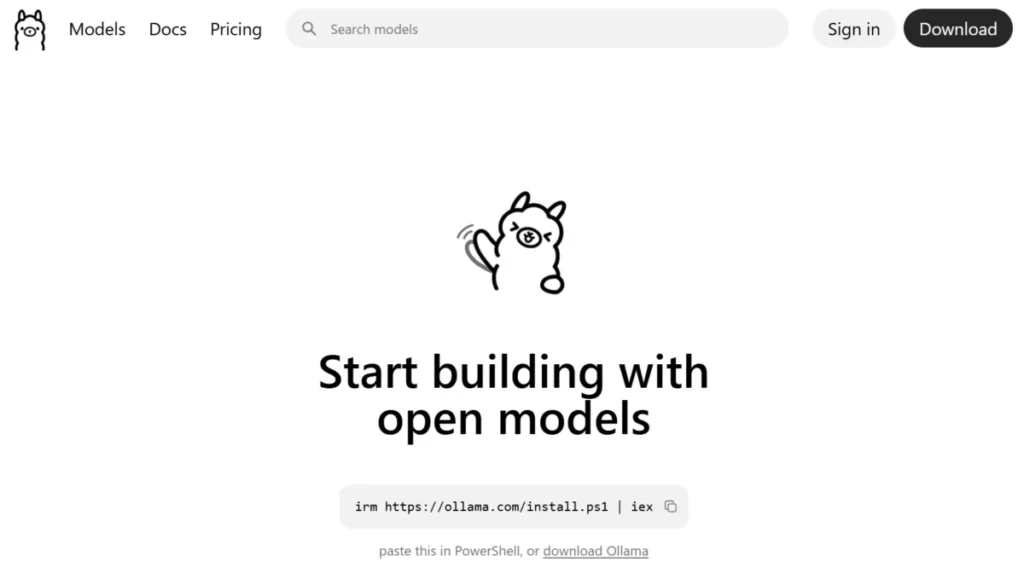
- OSの選択画面が表示されるので、「Windows」が選択されていることを確認します。
- 「Download for Windows」をクリックして、インストーラー(OllamaSetup.exe)をダウンロードします。
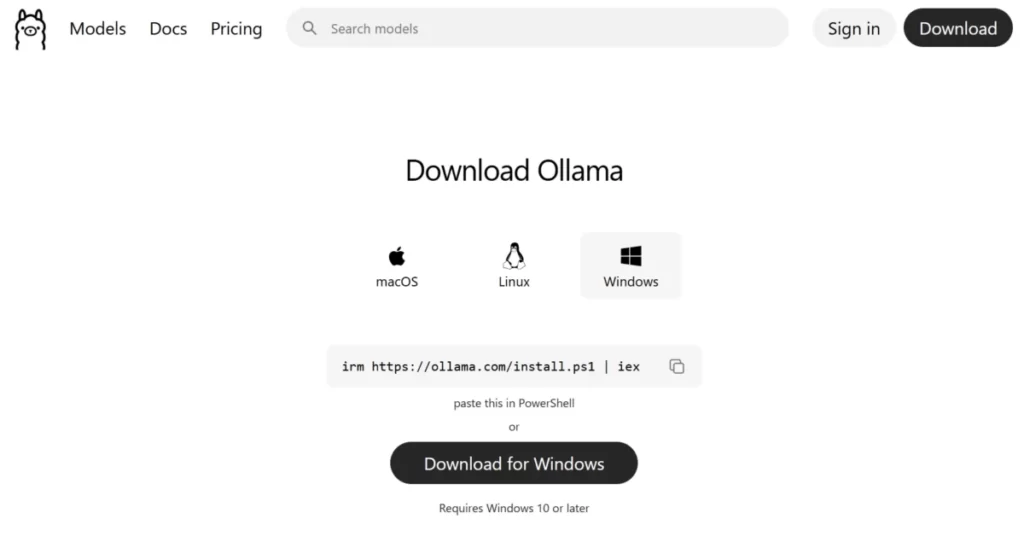
インストールの実行
ダウンロードしたファイルを使って、インストールを進めます。
- ダウンロードした「OllamaSetup.exe」をダブルクリックして起動します。
- 画面の指示に従って「Install」ボタンをクリックします。複雑な設定項目などは一切ありません。
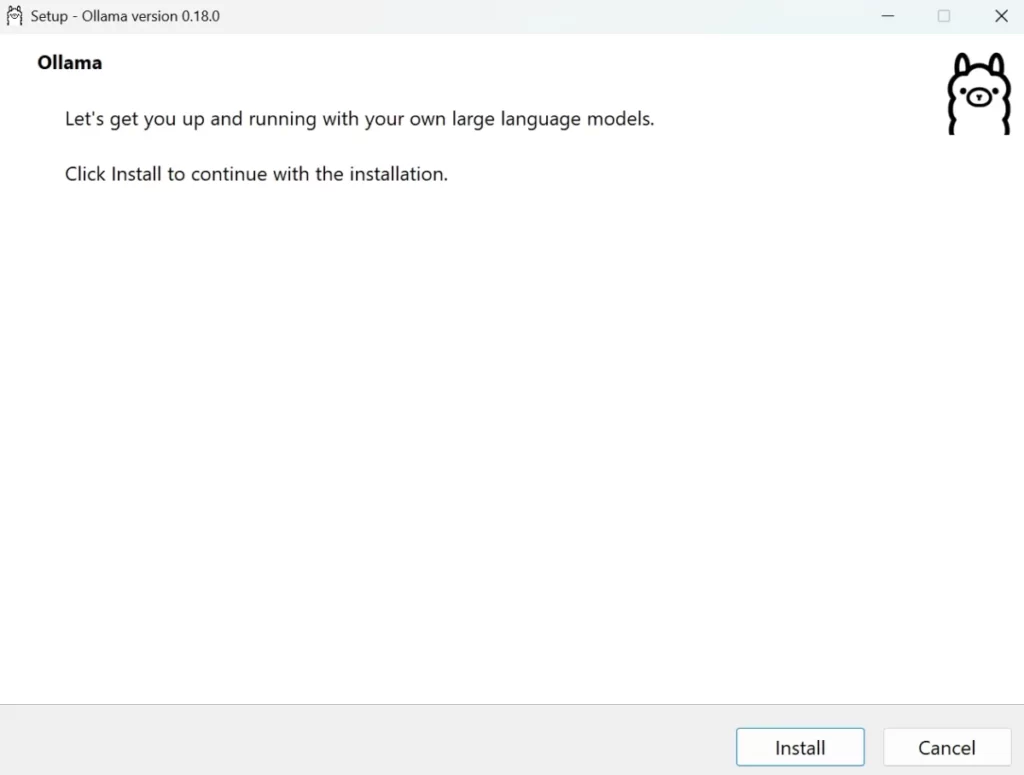
起動と常駐の確認
インストールが完了すると、自動的にOllamaが起動します。
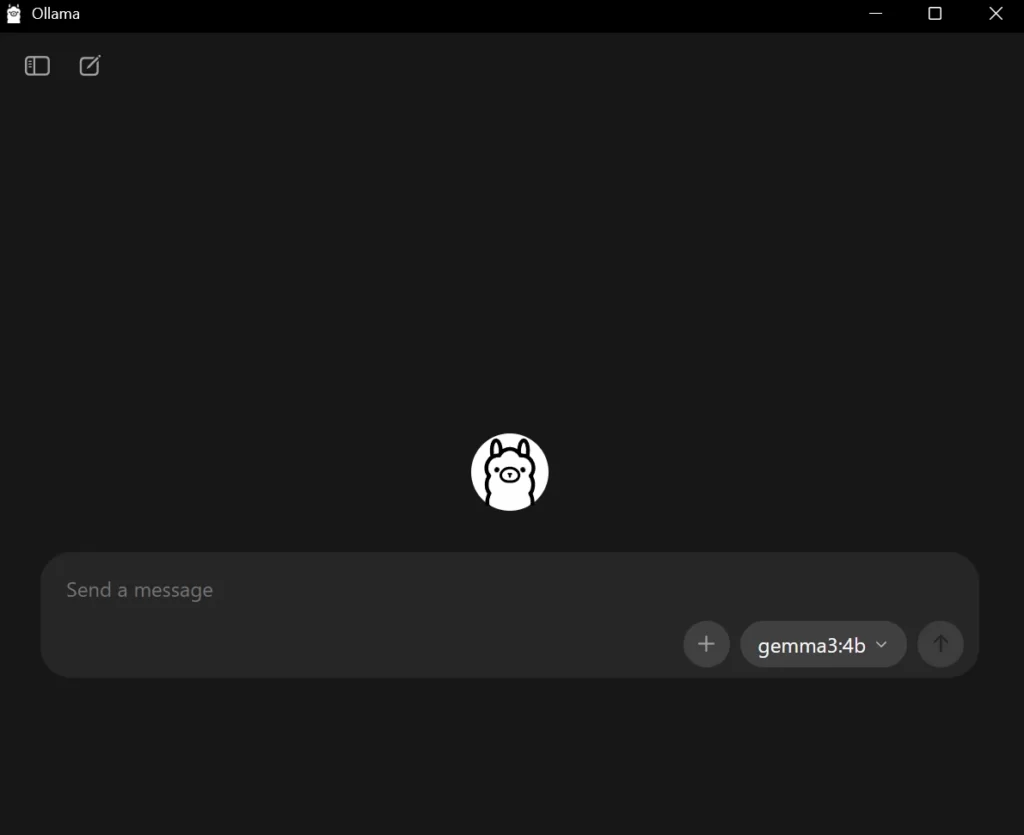
- Ollamaは、デスクトップ上に起動するのに加えて、タスクトレイに常駐します。
- 画面右下のタスクトレイ(時計の横のアイコン群)を開いて、Ollamaのアイコン(ラマのマーク)が表示されているか確認します。
- 表示されていれば、常駐しています。
設定の確認
Ollamaの画面左上にあるサイドバーを開いて、Settingsを確認します。
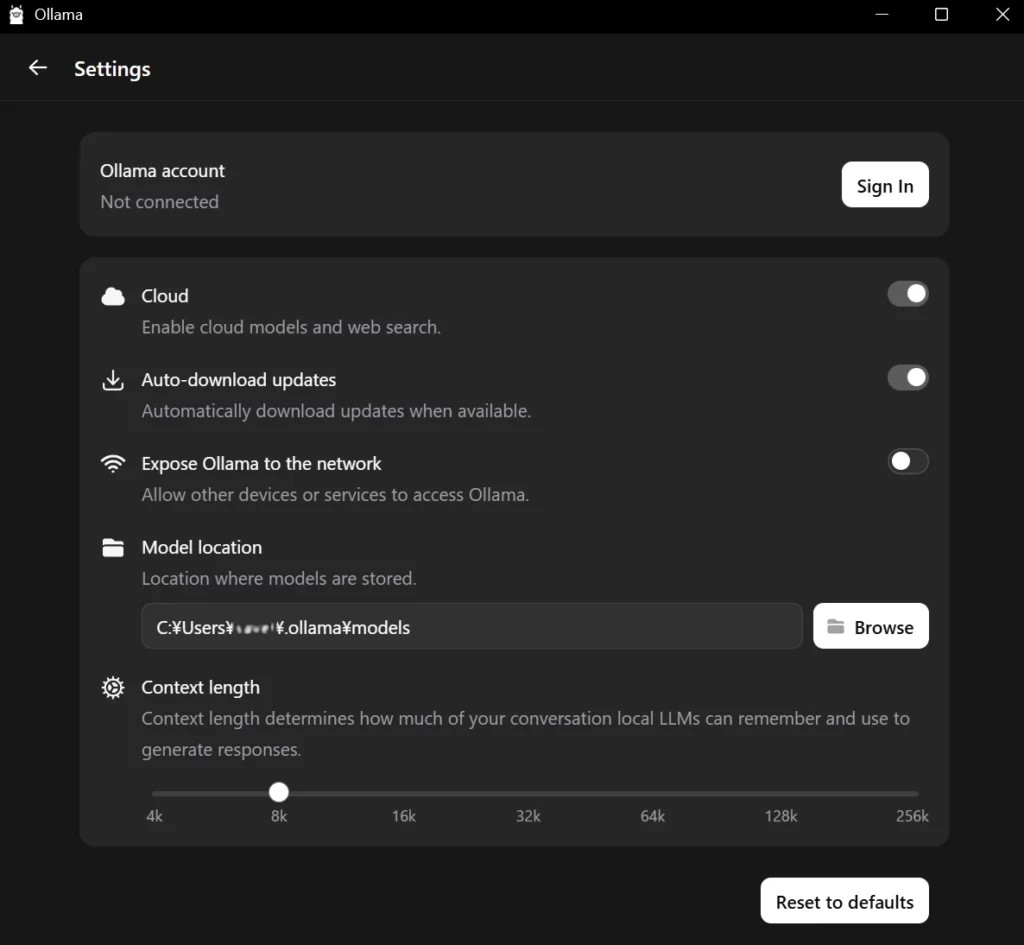
- Ollama account:
Ollamaにユーザー登録し、公式ライブラリに自作モデルを公開するなどの開発者向けの機能です。ローカルでAIを利用するだけであれば、Sign Inは不要です。 - Cloud:
オンにすると、ローカルのAIモデルだけでなく、クラウド上のAIモデルを呼び出したり、インターネット上の最新情報を検索して回答に含めることができます。 - Auto-download updates:
利用可能なアップデートがある場合、自動的にダウンロードします。 - Expose Ollama to the network:
他のデバイスやサービスがOllamaにアクセスできるようにします。オンにすると、同じネットワーク内の別のパソコンなどから、Ollamaを起動しているパソコンに接続して機能を使うことができるようになります。一人で使っているならOFFで良いです。 - Model location:
AIモデルを保存するフォルダです。ローカルのAIモデルは、数GB~数十GBとデータ容量が大きいので、余裕のあるドライブを選択しましょう。 - Context length:
ローカルLLMが会話をどれぐらい記憶して、回答生成に使用できるかを設定します。AIが一度のやり取りで記憶・処理できる文字数(トークン数)の上限であり、数値を上げれば長文を読み込めますが、その分、グラフィックボードのメモリ(VRAM)を多く消費します。
Context lengthは、以下のような使い分けを目安にしてください。
まずは8kで使い始めてみて、AIがチャットの流れを忘れてしまうなど、不便を感じるようでしたら、16kや32kを選ぶのが良いと思います。
- 4k ~ 8k(おすすめの基本設定)
- 用途:日常的なチャット、Obsidianのノート(1~2ページ程度)の要約やタグ付け、ブログ構成案の作成など。
- 所感:メモリ消費も少なく、通常はこの設定でも全く不便を感じません。
- 16k ~ 32k (長い文章を扱う場合)
- 用途:過去に書いたブログ記事などを丸ごと数本読み込ませて分析する場合や、長いプログラムのコードを一度に修正する場合など。
- 所感:メモリ消費が増えますので、メモリ容量にある程度の余裕が必要です。
- 64k 以上(基本的には非推奨)
- AIモデル自体が、ここまでの長文に対応していないことも多く、パソコンへの負荷も大きいため、普段使いには適していません。
OllamaアプリからAIモデルをダウンロードして対話する
インストールが完了しOllamaが起動したら、実際にAIモデルをダウンロードして対話してみましょう。
複雑なコマンド操作は不要で、すべて画面上から操作できます。
今回は、初めて使うAIモデルとしておすすめの軽量モデル「gemma3:4b」を試してみます。
「gemma3:4b」について
「gemma3:4b」について簡単に紹介します。
軽量で一般的なパソコンでも動作する点が、初めてのAIモデルとしておすすめです。
- 開発元は、Google(Geminiなどと同じ開発元によるオープンモデル)
- モデルサイズ:4B(約40億パラメータ)
- ダウンロードサイズ:約2.5~3GB程度
- 動作環境:高性能なグラフィックボード(GPU)を搭載していない一般的なパソコンでも比較的軽快に動作します。
- 用途:日常的なチャット、Obsidian等のノートの要約やタグ付け、ブログ構成案の検討など
AIモデルの検索とダウンロード
- Ollamaのチャット画面を開き、画面右下にあるAIモデルの選択ボタンを押し、AIモデルのリストから
gemma3:4bを選択するか、「Find model…」という検索窓にgemma3:4bと入力します。 gemma3:4bが選択された状態で、チャットで何か会話を始めると、選択したAIモデルがまだダウンロードされていなければ、ダウンロードが始まります。- モデルにもよりますが、数GB~数十GBの容量があるため、ダウンロード完了までしばらく待ちます。
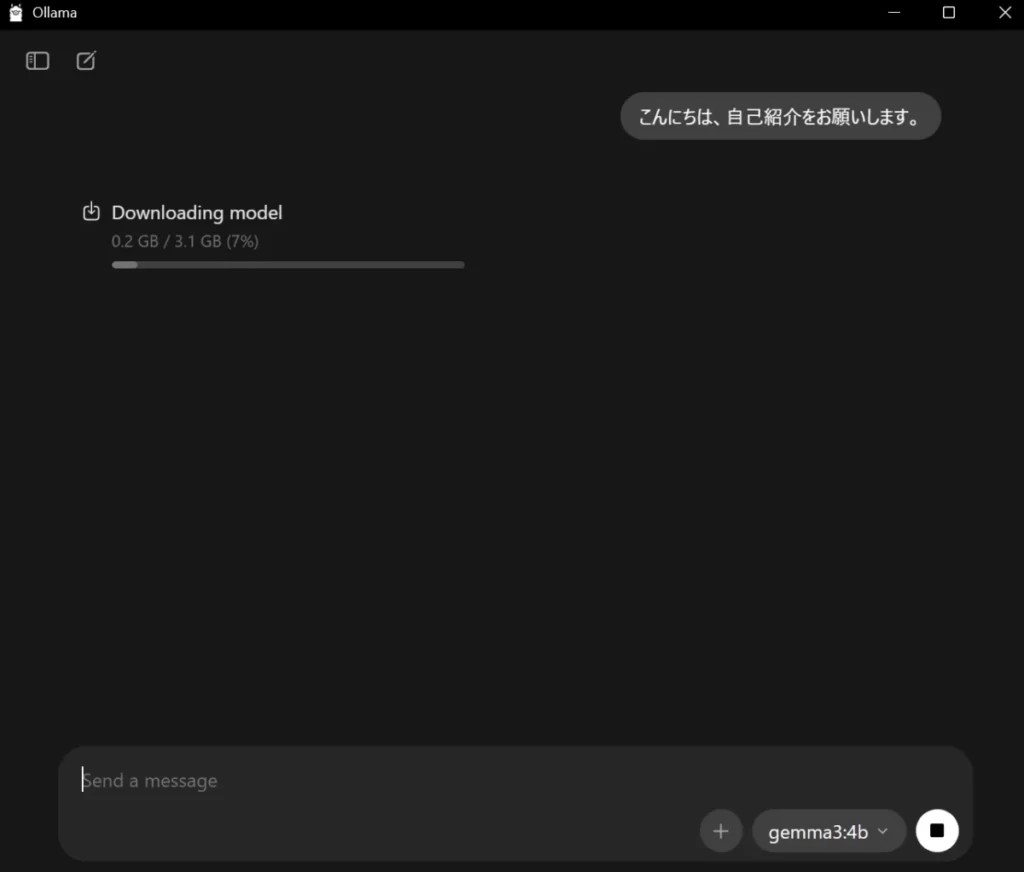
AIとの対話
ダウンロードが完了すると、そのまま画面下部の入力欄(Send a message)からAIと対話ができるようになります。
私の環境(RTX 5070搭載)では、待たされることなく非常にスムーズに回答が生成されました。これで、インターネットに繋がっていなくても動く、自分だけのローカルAI環境の完成です。
まとめ
今回はローカルAI実行エンジン「Ollama」のインストールから、最初のAIモデルを動かすところまでを実践しました。
実際にやってみた感想として、Pythonの環境構築や複雑な設定ファイルを触る必要がなく、驚くほど簡単にローカルAI環境を構築できました。また、GPUを搭載している環境であれば、自動でGPUを活用してくれるため、レスポンスも非常に快適です。
注意点として、ダウンロードするAIモデルのサイズが大きいとパソコンのストレージ(Cドライブ)を消費するため、不要になったモデルは適宜削除するなどの管理が必要です。
次回は、今回使用した「gemma3:4b」以外にも、文章作成やプログラミングなど、目的別にOllamaで動かせるおすすめの無料AIモデルを詳しく紹介します。



