
前回の記事では、自分のパソコン上で安全にAIを動かせる
完全無料の実行エンジン「Ollama」のインストール手順と、
最初の軽量モデル「gemma3:4b」の導入方法を解説しました。

Ollamaを導入すると、
世界中で公開されている様々な無料AIモデル(ローカルLLM)を
アプリから簡単にダウンロードして使うことができます。
しかし、いざ他のモデルを探してみると、
種類が多すぎて「どれを選べばいいのか分からない」と迷ってしまうかもしれません。
そこで今回は、ご自身のパソコンのスペックや
「AIに何をさせたいか」という目的に合わせて、
Ollama上で動かせるおすすめの日本語対応AIモデルを厳選して紹介します。
実際に私のデスクトップ環境(Core Ultra 7、メモリ32GB、RTX 5070)
で動かしてみた実体験も交えて解説しますので、ぜひ参考にしてください。
1. ローカルAIモデル選びの基本(PCスペックとの関係)
おすすめモデルを紹介する前に、モデル選びで最も重要な「パソコンのスペックとの関係」について触れておきます。
ローカルAIの賢さや処理速度は、パソコンの「メインメモリ(RAM)」とグラフィックボードの「VRAM(ビデオメモリ)」の容量に大きく依存します。Ollamaのモデルを探す際は、名前の最後についている「〇〇b(パラメータ数)」に注目してください。
- 軽量モデル(4B〜9Bクラス) 一般的なノートパソコンやミニPCでも比較的快適に動かせるサイズのモデルです。非常に動作が軽く、瞬時に回答を返してくれます。「ノートの要約」や「日常的なチャット」であれば、このサイズでも十分な性能を発揮します。
- 大規模モデル(14B〜32Bクラス) 大容量のメインメモリ(32GB以上)や、強力なグラフィックボード(RTXシリーズなど)を搭載したハイスペック環境向けのモデルです。データサイズが大きく処理に少し時間はかかりますが、日本語の表現力が格段に上がり、複雑な論理展開や長文の作成、プログラミングなどが可能になります。
2. Ollama公式サイトでのAIモデルの探し方
Ollamaで使えるモデルは、公式の検索ページ(https://ollama.com/search)から探すことができます。このページでは、世界中のモデルが「Popular(人気順)」や「Newest(新着順)」で並んでおり、上部のタグ(ボタン)をクリックすることで、機能ごとに絞り込み検索が可能です。
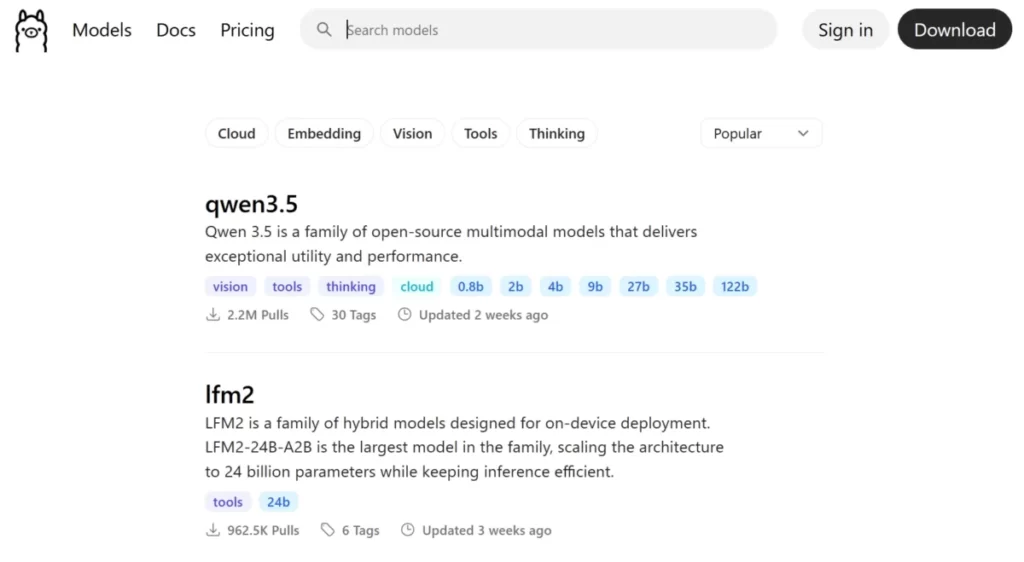
それぞれの検索タグが持つ意味を知っておくと、自分にぴったりのモデルが見つけやすくなります。
- Cloud(クラウド) 自分のパソコン(ローカル)ではなく、インターネット上のサーバーで処理を行う超巨大モデルなどを探す際に使用します。ローカルで安全に動かしたい場合は、このタグが付いていないモデル(あるいはサイズ指定が可能なモデル)を選びましょう。
- Embedding(埋め込み) 文章をAIが理解できる数値(ベクトル)に変換するための特殊なモデルです。チャット用途ではなく、RAG(独自の社内文書などを読み込ませるシステム)などを構築する開発者向けです。
- Vision(視覚 / マルチモーダル) テキストだけでなく、画像(スクリーンショットや写真)を読み込んで理解する能力を持ったモデルです。
- Tools(ツール連携) ObsidianのAIプラグインや外部ツールからの呼び出しに対して、「指定された形式を厳密に守って出力する(関数呼び出し)」能力に優れたモデルです。
- Thinking(論理推論) 複雑な問題に対して、順序立てて深く思考(推論)する能力に特化したモデルです。プログラミングや高度な文章構成などに向いています。
3. 目的別!Ollamaのおすすめ無料AIモデル
ここからは、具体的な目的別におすすめのモデルを紹介します。すべてのモデルは、Ollamaアプリ上部の「Find model…」の検索窓に名前を入力してモデルを選択してから、チャットを開始すると、まだダウンロードしていないモデルの場合は、ダウンロードが始まります。
① Obsidianなどのノート作成・要約向け(軽量・高速)
Obsidianで書いたメモをサッと要約させたり、適切なタグを提案させたりする用途には、レスポンスが速く、ツール連携(Tools)が得意な以下のモデルがおすすめです。
- gemma3:4b (Google) 前回の記事でも紹介した、バランスの取れた非常に優秀な超軽量モデルです。標準で日本語に流暢に対応しており、日常的なちょっとした質問や文章の要約に最適です。迷ったらまずはこれを入れておけば間違いありません。
- qwen3:8b (Alibaba) こちらも非常に動作が軽く、同サイズ帯のモデルの中では日本語の自然さがトップクラスです。gemma3よりも少しだけサイズが大きいため、より文脈に沿った自然な対話を楽しみたい場合のステップアップとして最適です。

- 試しに、前回の記事を書いたObsidianのMarkdownファイルを渡して
qwen3:8bに要約してもらいました。
② ブログ記事や長文の作成向け(高精度・大規模)
より自然な日本語で、構成のしっかりしたブログ記事の下書きを作らせたり、壁打ち相手として深く議論(Thinking)したりしたい場合は、大規模モデルの出番です。
- qwen3:32b (Alibaba) 非常に賢く、クラウド型の高性能AI(ChatGPTなど)に迫る論理的思考力と自然な日本語出力を持っています。私の環境(RTX 5070 / メモリ32GB)で動かしてみたところ、多少の生成時間はかかるものの、その回答の質の高さに驚きました。複雑な概念の解説や、長い文章の構造化などに威力を発揮します。
- mistral-small3.2 (Mistral AI) 24Bサイズの大規模モデルで、「必ずこの形式で出力して」といった指示(プロンプト)を厳密に守る能力に長けています。ブログの目次を特定のMarkdown形式で出力させたい場合などに重宝します。
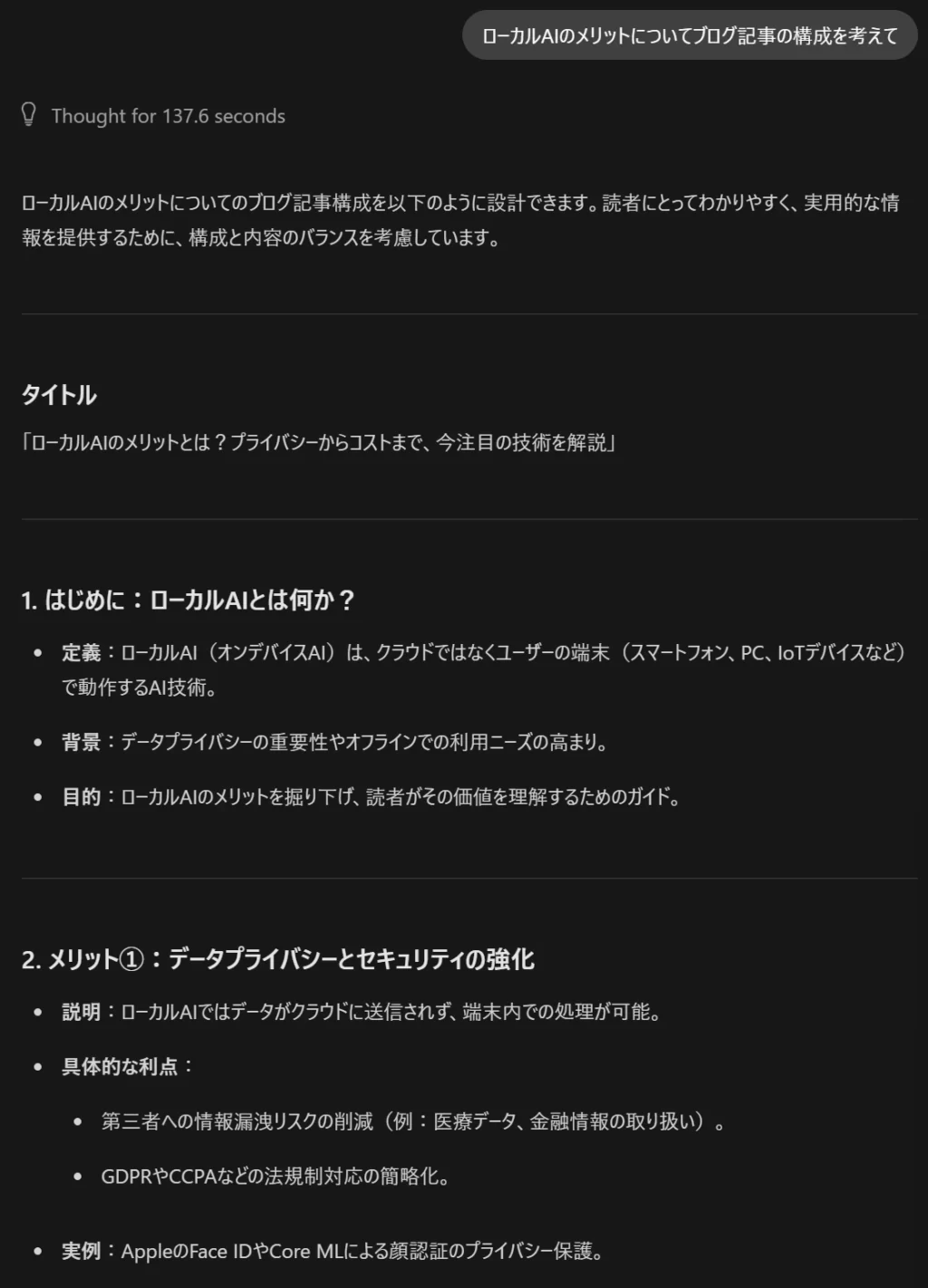
- 試しに「ローカルAIのメリットについてブログ記事の構成を考えて」と指示してみた結果です。
- スクリーンショットは一部ですが、メリットを6個挙げたあと、今後の展望や結論、読者に向けたQ&Aなど、ブログ記事としての構成を考えてくれました。
③ プログラミング・サーバー管理向け
ブログ構築のためのスクリプトを書かせたり、VPS(UbuntuやNginx)の設定ファイルのエラーを修正させたりする用途には、論理推論やコード生成に特化したモデルが便利です。
- deepseek-r1:8b (DeepSeek) 軽量でありながら、複雑な論理推論とコーディング能力に非常に定評があるモデルです。CursorなどのAIエディタと連携させて、裏側でサクサクとコードを書かせるのに向いています。
- qwen3-coder:30b (Alibaba) プログラミングの知識に特化して学習された大規模モデルです。複数ファイルにまたがるコードの修正や、複雑なサーバー構築の手順などを的確に生成してくれます。
④ マルチモーダル(画像読み込み)向け
Ollamaでは、スクリーンショットなどの画像を読み込ませて「これは何のエラー?」と質問できる「ビジョン(Vision)モデル」も利用できます。
- qwen3-vl:8b (Alibaba) 画像認識能力を持つ軽量モデルです。Ubuntu Serverのターミナルのエラー画面や、ツールの設定画面のスクショをサッと読み込ませて解説してもらう際に、非常に軽快に動作します。
※注意:画像を読み込ませる際のポイント
Ollamaで画像を読み込ませて解説してもらうには、モデルに「Vision(視覚)」の機能が備わっている必要があります。上記で紹介した「qwen3:8b」や「qwen3-coder」などのテキスト専用モデルに画像を投げても認識できないため、目的に合わせてVision対応モデル(qwen3-vlなど)に切り替えて使用してください。
4. 注意点:Ollamaで画像や音楽は「作れる」?
ここで一つ重要な注意点があります。
「AIを使ってブログのアイキャッチ画像や、動画のBGMを作りたい」と考える方もいるかもしれませんが、現在のOllamaの仕様では、画像、音楽、動画を「生成(作成)」することはできません。
Ollamaはあくまで「テキスト(文章やコード)」を出力することに特化したエンジンです(前述のVisionモデルによる画像の「読み込み・理解」は可能です)。もしローカル環境でゼロから画像を生成したい場合は、「Stable Diffusion」などの全く別のツールを導入する必要がありますので、目的を混同しないように注意しましょう。
【まとめ】おすすめAIモデル一覧表
OllamaのおすすめAIモデルを表にまとめました。ご自身のパソコン環境や目的に合わせて選んでみてください。
| モデル名(検索用) | サイズ | PC負荷 | タグ(機能) | 最適な用途・特徴 |
|---|---|---|---|---|
| gemma3:4b | 4B | 小 | – | 日常チャット、簡単な要約。最初の1本に最適。 |
| qwen3:8b | 8B | 小 | Tools, Thinking | 自然な日本語対話、アイデア出し、ノート整理。 |
| deepseek-r1:8b | 8B | 小 | Thinking | 論理推論、短いプログラミング、スクリプト作成。 |
| qwen3-vl:8b | 8B | 小 | Vision | 画像の読み込み(エラー画面の解析など)。 |
| mistral-small3.2 | 24B | 中〜大 | Tools, Vision | 複雑な指示の厳密な遵守、フォーマット指定出力。 |
| qwen3-coder:30b | 30B | 大 | Tools | 本格的なコーディング、サーバー設定ファイルの作成。 |
| qwen3:32b | 32B | 大 | Tools, Thinking | 高度な論理構成、ブログ記事作成、深い議論。 |
実際にいくつかのモデルを試してみた感想として、単なるテキストチャットであれば軽量な「gemma3:4b」や「qwen3:8b」で十分すぎる性能を感じました。さらに、RTX 5070を搭載したデスクトップ環境のパワーを活かして大規模な「qwen3:32b」を動かしてみると、ローカルAIの進化のスピードを肌で感じることができました。
注意点として、色々なモデルを試しているとパソコンのストレージ(Cドライブ)を数十GB単位で圧迫してしまいます。使わなくなったモデルは、コマンドプロンプトから ollama rm モデル名 と入力してこまめに削除することをおすすめします。
まずは気になるモデルをOllamaの検索窓から1つダウンロードして、ローカルAIの実力を体験してみてください。


