これまでの Next.js ブログサイト構築シリーズをまとめたページは以下の通りです。

前回の記事はこちらです。

記事を読み終えたとき、ページの一番下に「関連記事」が並んでいると、
つい次の記事もクリックしてしまいます。
大手メディアやブログサービスでは当たり前のように実装されているこの機能ですが、
自分で作った Next.js ブログに同じものを実装しようとすると、
「どうやって関連記事を自動で選べばいいのか」という問題にぶつかります。
今回の第17回では、この問題を解決します。
完成すると、記事ページの前後ナビゲーションの下に、
以下のような関連記事エリアが自動で表示されるようになります。
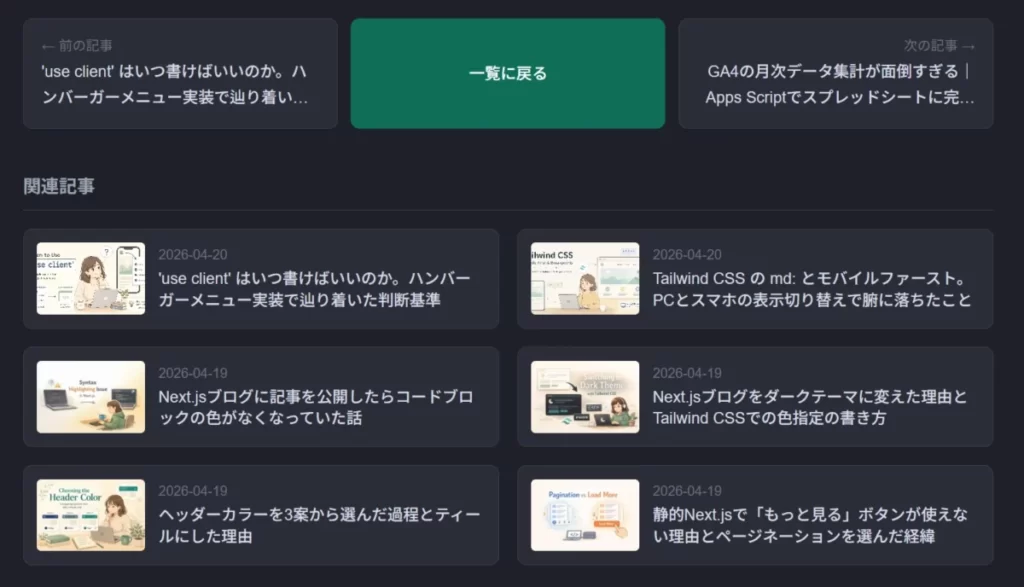
個別記事ページの下部に「関連記事」エリアが追加された状態です。
アイキャッチ画像・日付・タイトルが2列×3行のカードレイアウトで並んでいます。
関連性の高い記事が自動で選ばれて表示されています。
手動でリンクを貼る必要は一切ありません。
Markdown のフロントマターに設定済みの tags と category の情報をもとに、
システムが自動的に関連性の高い記事を選んで表示してくれます。
この記事では以下の内容を解説します。
- 関連記事を「どうやって自動で選ぶか」という設計の考え方
lib/posts.tsに関連記事取得関数を追加する具体的な手順- 個別記事ページに関連記事を2列×3行で表示するコードの追加方法
- 各コードが何をしているかの丁寧な解説
記事の前提条件と対象読者
この記事は、以下の環境と進捗を前提として手順を解説しています。
- Next.js のバージョン: Next.js 16.2 系( React 19)環境の App Router を使用しています。
- ビルド方式:
output: 'export'による静的エクスポートモードで動作しています。 - 対象読者: シリーズ第16回までを完了し、カテゴリーページとタグページの実装が完了している方を対象としています。
関連記事を「自動で選ぶ」仕組みをどう設計するか
実装の前に、まずどうやって関連記事を選ぶかという設計を考えました。
ここをしっかり考えておくと、コードを書く前に全体像が見えて作業がスムーズになります。
シンプルに「同じカテゴリーの記事を表示する」だけでも関連記事として成立します。
しかしカテゴリーは大きな分類なので、内容があまり近くない記事が表示されてしまうことがあります。
今回は、タグを優先してカテゴリーで補完するという2段階の方式を採用しました。
① 表示中の記事と同じタグを1つでも持つ記事を優先して選ぶ
↓ 6件に満たない場合
② 同じカテゴリーの記事で補完する
↓
③ 合計最大6件に絞り込むタグはカテゴリーより細かい分類なので、タグが一致する記事は内容が近い可能性が高いです。
タグで足りない分をカテゴリーで補完することで、「なるべく内容が近い記事」を優先しつつ、表示件数も確保できます。
表示件数を6件にした理由
2列表示のレイアウトでは、5件だと最後の1件が左列だけに表示されてバランスが崩れます。
6件(2列×3行)にすることで、見た目がきれいに整います。
今回変更するファイル
今回変更するファイルは2つだけです。
| ファイル | 操作 |
|---|---|
example-blog/lib/posts.ts | 関連記事取得関数を末尾に追加 |
example-blog/app/posts/[id]/page.tsx | インポートの追加・変数の追加・表示コードの追加 |
STEP 1:lib/posts.ts に関連記事取得関数を追加する
lib/posts.ts には、前回(第16回)でカテゴリーやタグを扱う関数を追加しました。
今回はさらにその末尾に、関連記事を取得する関数 getRelatedPosts を追加します。
Cursor などで example-blog/lib/posts.ts を開き、ファイルの末尾(最終行の下) に以下のコードをすべてコピーして貼り付け、保存してください。
// ============================
// 関連記事を取得する関数
// ============================
// 関連記事を最大6件返す(タグ一致優先 → カテゴリー補完 → 自身を除外)
export function getRelatedPosts(currentId: string, tags: string[], category: string): PostData[] {
const allPosts = getSortedPostsData();
// 自分自身を除いた全記事
const otherPosts = allPosts.filter((post) => post.id !== currentId);
// ① タグが1つ以上一致する記事を集める
const byTag = otherPosts.filter((post) =>
post.tags.some((tag) => tags.includes(tag))
);
// ② タグ一致の記事が6件に満たない場合、同じカテゴリーで補完する
// ただし、すでにタグ一致に含まれている記事は重複して追加しない
const tagIds = new Set(byTag.map((post) => post.id));
const byCategory = otherPosts.filter(
(post) => post.category === category && !tagIds.has(post.id)
);
// ③ タグ一致 → カテゴリー補完 の順に並べて最大6件に絞る
return [...byTag, ...byCategory].slice(0, 6);
}コードの意味を1つずつ解説
コードの量は少ないですが、初めて見る書き方がいくつかあります。1つずつ丁寧に説明します。
関数の定義部分
export function getRelatedPosts(currentId: string, tags: string[], category: string): PostData[] {この関数は3つの情報を受け取ります。
currentId:今表示している記事の ID(例:nextjs-setup)tags:今表示している記事のタグの一覧(例:['nextjs', 'vps'])category:今表示している記事のカテゴリー(例:'nextjs')
末尾の : PostData[] は「この関数は記事データの配列を返す」という意味の型宣言です。
これを書いておくと、返ってくるデータの形が保証されるため、後でコードを読んだときにわかりやすくなります。
自分自身を除外する
const otherPosts = allPosts.filter((post) => post.id !== currentId);filter() は配列を条件で絞り込むメソッドです。
条件に合うものだけを残して新しい配列を作ります。
post.id !== currentId は「この記事の ID が、今見ている記事の ID と違う」という条件です。
つまり、今表示している記事自身を除いた全記事が otherPosts に入ります。
自身を除外しないと「今読んでいる記事が関連記事として表示される」という奇妙な状態になってしまうため、この処理は必須です。
タグが一致する記事を集める
const byTag = otherPosts.filter((post) =>
post.tags.some((tag) => tags.includes(tag))
);少し複雑に見えますが、やっていることをひとことで言うと「この記事のタグが1つでも一致するか?」を調べているだけです。
2つのメソッドが使われています。
some() とは
配列の中身を1つずつ調べて、「1つでも条件を満たすものがあれば true を返す」メソッドです。
例:[1, 2, 3].some((n) => n > 2) → 3 > 2 が成り立つので true
includes() とは
配列の中に指定した値が含まれているかを調べるメソッドです。
例:['nextjs', 'vps'].includes('nextjs') → true
全体の流れ
post.tags → この記事のタグ一覧(例:['nextjs', 'markdown'])
.some((tag) => → タグを1つずつ取り出して調べる
tags.includes(tag) → 今表示中の記事のタグ一覧にそのタグが含まれるか
)タグが完全一致していなくても、1つでも一致すれば選ばれます。
重複を防ぐカテゴリー補完
const tagIds = new Set(byTag.map((post) => post.id));
const byCategory = otherPosts.filter(
(post) => post.category === category && !tagIds.has(post.id)
);new Set() とは
重複を許さないデータの入れ物です。同じ値を複数入れようとしても、自動的に1つだけになります。
例:new Set(['a', 'b', 'a']) → {'a', 'b'}
ここでは、タグ一致で集めた記事の ID を Set に入れておきます。
なぜ Set を使うのか
カテゴリー補完で記事を追加するとき、タグ一致ですでに選ばれた記事を重複して追加しないようにするためです。
!tagIds.has(post.id) の ! は「ではない」という意味です。
全体で「同じカテゴリーの記事のうち、タグ一致でまだ選ばれていない記事だけ」という条件になります。
最大6件に絞り込む
return [...byTag, ...byCategory].slice(0, 6);スプレッド構文(...)とは
配列の前に ... を付けると、配列の中身を展開することができます。
// 2つの配列を1つにまとめる例
[...[1, 2], ...[3, 4]] → [1, 2, 3, 4]ここではタグ一致の記事(byTag)を先頭に並べ、その後ろにカテゴリー補完の記事(byCategory)をつなげて1つの配列にしています。
.slice(0, 6) とは
配列の先頭から6件だけ切り取るメソッドです。これで最大6件に絞り込まれます。
タグ一致が6件以上あればカテゴリー補完は使われず、タグ一致が少なければカテゴリー補完で6件になるまで補います。
STEP 2:app/posts/[id]/page.tsx を編集する
次に、個別記事ページのファイル example-blog/app/posts/[id]/page.tsx に3つの変更を加えます。
変更①:インポート文に getRelatedPosts を追加する
Cursor などで example-blog/app/posts/[id]/page.tsx を開き、ファイルの1行目を確認してください。
以下のような行があります。
import { getPostData, getSortedPostsData } from '../../../lib/posts';この行を以下のように書き換えてください(getRelatedPosts を追加するだけです)。
import { getPostData, getSortedPostsData, getRelatedPosts } from '../../../lib/posts';import とは、別のファイルで定義した関数をこのファイルで使えるようにする宣言です。
先ほど lib/posts.ts に追加した getRelatedPosts 関数をここで読み込みます。
これを書かないと、次のステップで getRelatedPosts を呼び出したときに「そんな関数は存在しない」というエラーになります。
変更②:relatedPosts 変数を追加する
次に、記事データを取得している処理の直後に1行追加します。
注意:このファイルには getPostData(id) という記述が2か所あります。
Ctrl + F で getPostData(id) と検索すると、2件ヒットします。
今回変更するのは、export default async function Post という関数の中にある方です。
![Cursorでapp/posts/[id]/page.tsxを編集する際にgetPostData(id)を検索してexport default async functionの中にあるgetPostData(id)が表示されている画像](https://lifework-blog.com/wp-content/uploads/2026/04/nextjs-search-getPostData_id-1024x338.webp)
Ctrl + F で検索した際に2件ヒットしている様子のスクリーンショットです。
上の方にあるgenerateMetadata関数の中の1件目ではなく、下の方にあるexport default async function Post関数の中の2件目が対象です。
export default async function Post 関数の中には、以下のような行があります。
const postData = getPostData(id);この行の直後に、以下の1行を追加してください。
const relatedPosts = getRelatedPosts(postData.id, postData.tags ?? [], postData.category ?? '');追加後はこのような状態になります。
const postData = getPostData(id);
const relatedPosts = getRelatedPosts(postData.id, postData.tags ?? [], postData.category ?? '');
// 全記事データを取得して、前後の記事を見つける
const allPosts = getSortedPostsData();?? とは(ヌル合体演算子)
?? は「左側が null(値なし)または undefined(未定義)のときだけ、右側の値を使う」という記号です。
| 書き方 | 意味 |
|---|---|
postData.tags ?? [] | タグが設定されていない記事の場合は空の配列 [] を使う |
postData.category ?? '' | カテゴリーが設定されていない記事の場合は空文字 '' を使う |
フロントマターにタグやカテゴリーを設定していない記事が1つでもあると、null や undefined が渡されてエラーになります。?? を使うことで、そのような記事でも安全に動作するようになります。
変更③:関連記事の表示コードを追加する
最後に、前後ナビゲーション(「前の記事」「次の記事」のボタンエリア)の直後に関連記事の表示コードを追加します。
ファイルの末尾付近に </nav> という行があります。
その行の直後、</div> の前に以下のコードを挿入してください。
{/* 関連記事 */}
{relatedPosts.length > 0 && (
<section className="mt-10">
<h2 className="text-base font-bold text-[#9ca3af] mb-4 pb-2 border-b border-[#3a3f4a]">
関連記事
</h2>
<div className="grid grid-cols-1 md:grid-cols-2 gap-4">
{relatedPosts.map((related) => (
<Link
key={related.id}
href={`/posts/${related.id}`}
className="flex gap-3 bg-[#2a2d38] border border-[#3a3f4a] rounded-lg p-3 hover:border-[#4a5060] transition-colors"
>
{/* アイキャッチ画像 */}
<div className="relative w-24 h-16 flex-shrink-0 bg-[#1e2028] rounded overflow-hidden">
{related.ogImage && related.ogImage !== '' ? (
<Image
src={related.ogImage}
alt={related.title}
fill
className="object-cover"
/>
) : (
<div className="absolute inset-0 flex items-center justify-center text-[#3a3f4a]">
<svg className="w-6 h-6" fill="none" stroke="currentColor" viewBox="0 0 24 24">
<path strokeLinecap="round" strokeLinejoin="round" strokeWidth={1}
d="M4 16l4.586-4.586a2 2 0 012.828 0L16 16m-2-2l1.586-1.586a2 2 0 012.828 0L20 14m-6-6h.01M6 20h12a2 2 0 002-2V6a2 2 0 00-2-2H6a2 2 0 00-2 2v12a2 2 0 002 2z" />
</svg>
</div>
)}
</div>
{/* タイトルと日付 */}
<div className="flex flex-col justify-center min-w-0">
<p className="text-xs text-[#6a7080] mb-1">{related.date}</p>
<p className="text-sm font-medium text-[#d4d8e2] leading-snug line-clamp-2">
{related.title}
</p>
</div>
</Link>
))}
</div>
</section>
)}表示コードのポイント解説
関連記事が0件のときは表示しない
{relatedPosts.length > 0 && (
...
)}relatedPosts.length > 0 は「関連記事が1件以上ある」という条件です。&& は「かつ」の意味で、条件を満たすときだけ右側の内容を表示します。
関連記事が0件の場合は「関連記事」という見出しすら表示されないため、すっきりした表示になります。
リスト表示で key が必須な理由
{relatedPosts.map((related) => (
<Link key={related.id} ...>map() でリストを表示するとき、各要素に key という属性が必須になります。
React は画面の一部を更新するとき、どの要素が変わったかを効率よく判断するために key を使います。key がないと、React はリストのどこが変わったかを正確に把握できず、余計な再描画が起きたり、表示がずれるバグが起きる可能性があります。
記事の ID はすべて異なる値なので、key として使うのに適しています。
スマートフォンでは1列、パソコンでは2列
<div className="grid grid-cols-1 md:grid-cols-2 gap-4">grid-cols-1:スマートフォン表示では1列md:grid-cols-2:横幅 768px 以上の画面では2列に切り替わる
md: というプレフィックスは Tailwind CSS の「レスポンシブ対応」の書き方です。
1つのクラスを書くだけで、画面サイズに応じたレイアウト切り替えが実現できます。
アイキャッチ画像がない記事はアイコンで代替
{related.ogImage && related.ogImage !== '' ? (
<Image src={related.ogImage} alt={related.title} fill className="object-cover" />
) : (
<div>...</div>
)}アイキャッチ画像(ogImage)が設定されている記事は画像を表示し、設定されていない記事は代わりに画像アイコン(SVG)を表示します。
これにより、アイキャッチ画像の有無にかかわらずレイアウトが崩れません。
flex-shrink-0 は「画像エリアが縮まないようにする」指定で、タイトルが長い記事でも画像のサイズが変わらないようにしています。min-w-0 はタイトルエリアの最小幅をゼロにする指定で、長いタイトルがはみ出さずに省略表示されるようにするために必要です。
タイトルが長くても2行で省略
<p className="text-sm font-medium text-[#d4d8e2] leading-snug line-clamp-2">line-clamp-2 は Tailwind CSS のクラスで、テキストを2行で切り詰めて末尾を ... で省略する指定です。
タイトルが長い記事でもカードの高さが揃い、レイアウトが崩れません。
STEP 3:ローカルで動作確認する
コードの編集が終わったら、本番環境に反映する前にローカルで動作確認を行います。
npm run devブラウザで任意の記事ページを開き、前後ナビゲーションの下に「関連記事」が表示されていることを確認してください。
個別記事ページの下部に「関連記事」エリアが表示されている状態のスクリーンショットです。
前後ナビゲーションボタンの下に「関連記事」という見出しが表示され、その下にアイキャッチ画像・日付・タイトルが2列で並んだカードが6件表示されていることが確認できます。
STEP 4:ビルドとデプロイを実行する
ローカルで正しく表示されていることを確認したら、開発サーバーを Ctrl + C で停止してから、以下のコマンドを実行してください。
./deploy.shdeploy.sh はビルドと VPS へのファイル転送を一括で実行するスクリプトです。
コマンド1つで本番環境への反映が完了します。
動作確認
デプロイ完了後、以下の項目を順番に確認してください。
- 個別記事ページの下部に「関連記事」が表示されること
- 関連記事のカードをクリックして、対応する記事ページへ遷移すること
- アイキャッチ画像が設定されていない記事は、画像アイコンが表示されること
- スマートフォン表示では1列、パソコン表示では2列になること
まとめ
今回は Next.js ブログの個別記事ページに、関連記事を自動表示する機能を実装しました。
変更したファイルは2つだけで、コードの量も少ないです。
しかし実装を通じて、1つ気づいたことがありました。
タグを丁寧に設定することが、関連記事の精度に直結するということです。
関連記事の自動表示は、タグが一致する記事を優先しています。
タグが一致する記事が無い、あるいは少なければ、カテゴリーが一致する記事を表示するようにしていますが、関連記事を読んでもらおうと思うと、意図してタグを付けるという工夫が必要になります。
記事の中で、少しだけ触れたものをタグにするよりは、メインテーマに近いものをタグとして選んでおくことで、より関連性の強い記事が選ばれるようになり、読者の利便性を高めることになります。
書く側としても、タグを付けるときに、将来的に記事同士のつながりを意識して付けるようにすることで、ブログ全体の記事構成にも良い影響を与えてくれると思います。
今回の作業では、タグは1つでも一致している記事から日付の新しいものが選ばれるようになっていますが、今後、閲覧数カウンターのデータベースが完成した段階で、「閲覧数が多い記事を優先して表示する」というロジックへの改善も検討しています。
タグが一致する記事の中でも、より多くの読者に読まれた記事が優先的に表示されれば、関連記事の質がさらに上がるはずです。
次回は静的エクスポートモードからサーバーモードへの切り替えと、SQLite を使った独自閲覧数カウンターの導入を行います。これはシリーズ全体で最も大きなアーキテクチャの転換点になります。
▼ この回の手順には書かなかった話を、別サイトにまとめています。

次回の記事はこちらです。