
前回の記事では、自分のパソコン上でAIを動かせる「Ollama」のインストールから、
アプリ画面を使った基本的な操作方法までを解説しました。

アプリ画面(GUI)から使いたいモデルを選んで話しかけるだけでも十分に便利ですが、
Ollamaにはコマンドライン(CUI)を使ったより高度な操作方法が用意されています。
「黒い画面にコマンドを打ち込む」と聞くと難しそうに感じるかもしれませんが、
CUIを使うことで、不要になったAIモデルを削除してパソコンの容量を確保したり、
AIの性格(創造性や記憶力など)を自分好みに細かくカスタマイズしたりと、
ローカルAIの真の力を引き出すことができます。
この記事は、Ollamaのアプリ操作には慣れてきて
「もう少し使いこなしたい」と感じている方に特におすすめです。
OllamaをCUIで操作するための準備と、
すべての基本コマンド、対話モード専用のコマンド、
そしてAIの挙動を操るパラメータの全一覧を分かりやすく解説します。
OllamaのCUI操作:ターミナルの起動準備
Ollamaのコマンドを入力するには、お使いのOSに標準で搭載されている「ターミナルアプリ」を起動するだけです。特別なソフトを追加でインストールする必要はありません。
- Windowsの場合:「Windows Terminal」や「PowerShell」、「コマンドプロンプト」を起動します。
- macOSの場合:「ターミナル (Terminal.app)」を起動します。
- Linux(Ubuntu系)の場合:「端末 (GNOME Terminal)」などを起動します。

上の画面は、Windowsで、PowerShellを起動した画面です。
Ollamaがバックグラウンドで起動している状態(タスクトレイにアイコンがある状態)で、この画面にコマンドを打ち込んでいきます。
Ollamaの基本コマンド全一覧(全15種)
ターミナルで入力する基本の構文は ollama <コマンド> <オプション> です。 現在利用できる全15種類のコマンドは以下の通りです。
| コマンド | 意味・概要 |
|---|---|
run | モデルを実行(対話モード起動)。未取得時は自動ダウンロードします |
pull | モデルのダウンロードのみを行います(実行はしません) |
list (または ls) | ダウンロード済みのモデル一覧を表示します |
ps | 現在実行中(メモリ展開中)のモデル一覧を表示します |
rm | 指定したモデルを削除します |
stop | 実行中のモデルを停止し、メモリを解放します |
cp | モデルをコピーして別の名前を付けます |
create | 設定ファイル(Modelfile)から独自のモデルを作成します |
show | モデルの詳細情報(ライセンスやシステムプロンプトなど)を表示します |
push | 自作モデルをOllamaの公式レジストリにアップロードします |
serve | Ollamaのサーバーを手動起動します(通常は自動起動のため不要) |
signin | ollama.comのアカウントにサインインします |
signout | ollama.comのアカウントからサインアウトします |
launch | 外部のアプリケーション(AIコーディングツールなど)を起動・設定します |
help | コマンドの詳しい使い方やヘルプを表示します |
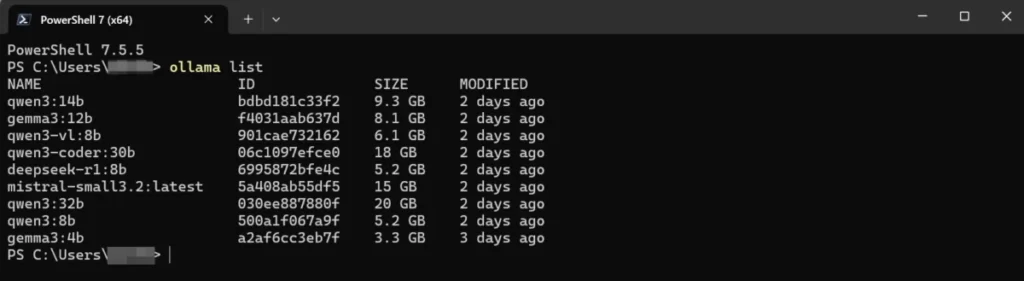
ollama listを実行した結果です。ダウンロード済みのモデル一覧が表示されています。
Ollamaで普段よく使う基本コマンド
日常的にOllamaを使う上で、必ず覚えておきたい主要なコマンドです。
モデルを実行して対話を開始するコマンドです。
ollama run gemma3:4bダウンロード済みのモデルと、そのデータサイズを確認します。
ollama list不要になったモデルを削除します。 ローカルAIモデルは数GB〜数十GBのサイズがあるため、私の環境でも色々なモデルを試しているとすぐにCドライブの容量が圧迫されてしまいました。使わなくなったモデルは、このコマンドでこまめに削除することをおすすめします。
ollama rm gemma3:4b現在メモリ(VRAM)を消費してバックグラウンドで動いているモデルを強制終了させます。別の重い作業をする際などに有効です。
ollama stop gemma3:4bモデル管理や外部連携のコマンド
独自モデルの作成や、外部サービスとの連携を行うためのコマンドです。
モデルの設定や役割を記述した「Modelfile(AIの設計図のようなファイル)」を読み込み、自分専用のモデルを作成します。
ollama create my-bot -f Modelfileモデルのライセンスや構成情報を確認します。
ollama show gemma3:4bコマンドの詳しい使い方が分からなくなった時は、ヘルプで確認できます。
ollama help runOllamaの対話モード専用「スラッシュコマンド」全一覧
ollama run を実行し、プロンプトが >>> に変わった「対話モード」の最中にだけ使える特殊なコマンドです。必ず先頭にスラッシュ(/)を付けて入力します。
| コマンド | 意味・概要 |
|---|---|
/? または /help | スラッシュコマンドの一覧と使い方を表示します |
/bye | 対話モードを終了し、通常のターミナル画面に戻ります |
/clear | 現在の会話履歴(コンテキスト)をすべて消去し、記憶をリセットします |
/save <名前> | 現在の設定状態を引き継いで、新しい別のモデルとして保存します |
/set | システムプロンプトやパラメータを一時的に設定・変更します |
/show | 現在動かしているモデルの設定内容や詳細情報を確認します |
""" (番外) | 複数行入力モードの開始・終了を切り替えるトリガーです。再度入力するまで改行しても送信されません |
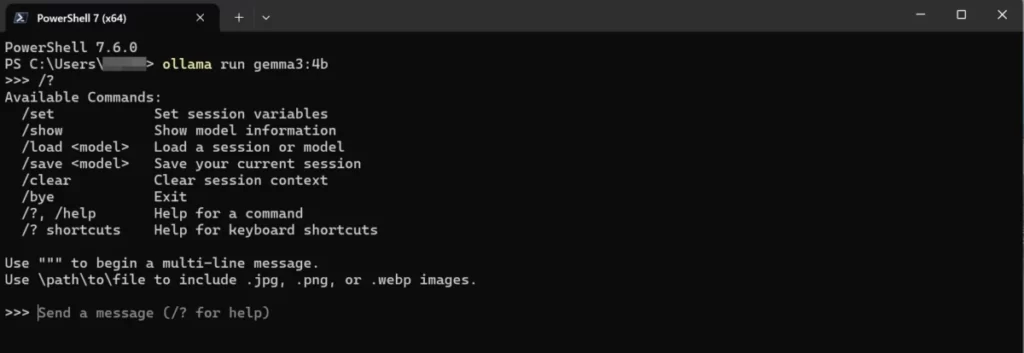
上の画像は、
ollama runでOllamaを起動したあと、/?でスプラッシュコマンドの一覧を表示させたところです。
対話モードコマンドの詳細な使い方
会話の文脈をリセットして、新しい話題を始めたい時に使います。AIが前の会話に引きずられておかしな回答をするようになった場合に便利です。
>>> /clear対話を終了するコマンドです。キーボードの Ctrl + D でも同じように終了できます。
>>> /byeAIに対する前提条件(システムプロンプト)を設定します。
>>> /set system あなたはプロの編集者として、私の文章を厳しく校正してください。長文を改行しながら入力したい場合は、"""(トリプルクォート)を入力してEnterを押します。再度 """ を入力するまで、送信されずに入力を続けられます。
>>> """
ここに複数行の
テキストを入力します。
"""OllamaでAIの性格を操る!パラメータ(/set parameter)全一覧
対話モード中に /set parameter <パラメータ名> <数値> と入力することで、AIの挙動を細かく制御できます。設定できる全パラメータを一覧表にまとめました。
| パラメータ名 | 意味(目的) | デフォルト値(目安) |
|---|---|---|
temperature | 回答のランダム性(創造性)を制御します | 0.8 |
top_k | 次の単語候補をK個に絞ります。値が高いほど多様な回答、低いほど保守的な回答になります | 40 |
top_p | 確率の合計がPになるまでの候補から選びます | 0.9 |
min_p | 最低限必要な確率の割合を指定します | 0.0 |
repeat_penalty | 同じ単語を繰り返すことへのペナルティの強さです | 1.1 |
repeat_last_n | 繰り返しの判定で過去に遡る単語数を指定します | 64 |
mirostat | Mirostatサンプリング機能を有効化します | 0 (無効) |
mirostat_eta | Mirostatの学習率を調整します | 0.1 |
mirostat_tau | Mirostatの目標エントロピーを調整します | 5.0 |
num_ctx | 一度に記憶・処理できるトークン数(コンテキストサイズ)です | 2048 |
num_predict | 生成する最大トークン数(文字数の上限)です | -1 (無制限) |
stop | テキスト生成を強制終了する文字列(ストップワード)です | なし |
seed | 乱数生成のシード値を固定します(回答の再現用) | 0 (ランダム) |
回答のランダム性・創造性を変えるパラメータ
最もよく使うのが temperature(温度感)です。 数値を下げる(例:0.1)と、事実に基づいた一貫性のある固い回答になります。プログラミングのコード生成や、事実確認をさせたい場合に適しています。
逆に数値を上げる(例:1.5)と、より創造的で多様な回答になります。ブログのアイデア出しや物語の作成などに適しています。
私が実際に試した感想として、temperature 0.1 に下げてコマンドの使い方を質問すると、余分な前置きなしに箇条書きで正確な答えが返ってくるようになりました。逆にデフォルトの 0.8 前後だとブログのアイデア出しなどにはちょうどよい「遊び」のある回答が出てきます。まず temperature だけ変えてみるのが、パラメータ沼への一番の入口です。
>>> /set parameter temperature 0.1記憶力や文章の長さを制限するパラメータ
num_ctx は、AIが一度に記憶できる会話の長さ(トークン数:AIが処理する単語の破片のようなもので、文字数の目安になります)を指定します。 デフォルトは2048ですが、長い文章を要約させたい場合などは数値を増やす必要があります。
私の環境(メモリ32GB、RTX 5070)で試したところ、この数値を 8192 や 16384 のように大きくすると、グラフィックボードのVRAMとパソコン本体のメインメモリの消費量が跳ね上がりました。最初はデフォルトのまま使い、AIが過去の会話を忘れてしまうと感じた場合にのみ、徐々に数値を引き上げていくのが安全な使い方です。
>>> /set parameter num_ctx 4096回答の長さを制限したい場合は、num_predict を指定します。デフォルトは -1(無制限)で、制限を設けたい場合にのみ指定します。
>>> /set parameter num_predict 256繰り返しの防止と高度な設定
AIが同じフレーズをループして喋り続ける場合は、repeat_penalty の数値を少し上げます(例:1.2)。
また、mirostat 関連のパラメータは、テキストの自然さを一定に保つための高度なアルゴリズムです。これらを有効にすると temperature などの設定が一部無視されるようになります。通常はデフォルトのままで問題なく動作するため、上級者向けの設定と言えます。
実践:自分好みのAIモデルを作って保存してみよう
ここまで学んだコマンドとパラメータを組み合わせて、「事実のみを硬いトーンで答える専用モデル」を作り、保存する一連の流れをやってみましょう。
まず、ベースとなるモデルを起動します。
ollama run gemma3:4b事実を重視させるため、ランダム性(temperature)を下げます。
>>> /set parameter temperature 0.1AIの役割(システムプロンプト)を設定します。
>>> /set system あなたは優秀なアシスタントです。推測を排除し、事実のみを簡潔に回答してください。この設定状態を、新しい名前(ここでは strict-gemma とします)で保存します。
>>> /save strict-gemma対話モードを終了します。
>>> /byeこれで、次回からはターミナルで ollama run strict-gemma と打ち込むだけで、いつでもこの硬い設定のAIを呼び出すことができるようになります。

上の画面は、
strict-gemmaで、「WindowsとMac、どちらを買うべきですか?」と質問したときの回答です。パラメータなどを設定せずに質問した場合に比べて、非常に簡潔な、ある意味、「愛想のない」回答になっていると思います。
なお、上記で保存した strict-gemma を削除する場合は、以下のコマンドを入力してください。
ollama rm strict-gemmaまた、 /set で変更した temperature などの設定は、対話モードを終了すると、すべて自動的にリセットされます。元のモデル自体の設定が上書きされることはありませんので、安心してください。
まとめ
今回は、OllamaをCUI(コマンドライン)で操作するための全コマンドとパラメータを解説しました。
アプリ画面のチャット欄に入力するだけの手軽さもOllamaの魅力ですが、CUIからコマンドやパラメータを操作することで、不要なモデルの削除によるストレージ管理や、「事実だけを固く答えるAI」といった自分好みのカスタマイズが可能になります。
パラメータを極端な数値に変更すると、AIが意味不明な言語を話し出すこともありますが、それもローカルAIならではの面白い実験です。まずは temperature を変えて回答がどう変化するかなど、気軽にターミナルから設定をいじって遊んでみてください。


コメント