これまでの Next.js ブログサイト構築シリーズをまとめたページは以下の通りです。

前回の記事はこちらです。
前回の第18回では、
Next.js ブログを静的エクスポートモードからサーバーモードに切り替え、
SQLite データベースを導入して、閲覧数カウンター用のテーブルを3つ作成しました。
ただし、第18回が終わった時点では「器を作っただけ」の状態でした。
テーブルの中身はまだ空で、閲覧数のカウントはまだ動いていません。
今回はいよいよ、その器に「仕組み」を入れます。
記事ページを開くたびに SQLite にカウントを書き込む API を作り、
蓄積した閲覧数をページに表示するところまでを実装します。
Google アナリティクス(GA4)があれば閲覧数は把握できますが、
独自カウンターには別の価値があります。
自分のサイト上でランキングを表示したり、特定の記事の数字を自由に使ったりできます。
データは完全に自分のものになります。
「自分のブログのデータを自分で管理・活用したい」という人には、作る価値がある仕組みです。
この記事では、自分が閲覧数を確認するために、
SSH 接続1回でレポートを出力できる Bash スクリプトも作成します。
この記事で実装するのは以下の4つです。
lib/db.ts:SQLite 接続を共通化する関数app/api/views/route.ts:閲覧数を記録・取得する APIcomponents/ViewCounter.tsx:閲覧数を表示するコンポーネント~/stats.sh:閲覧数レポートを出力する Bash スクリプト
実装前に決めたこと
コードを書き始める前に、いくつか設計上の決め事をしました。
コードの意味を理解するためにも、先に読んでおいてください。
トップページはカウント対象にしない
今回実装する閲覧数カウンターは、個別記事ページのみを対象にします。
トップページ(/)はカウント対象外にしました。
理由は次の回(第20回)で実装する「人気記事ランキング」に関係します。
ランキングは「記事の人気度」を示すものなので、トップページが混入すると意味をなしません。
記事ページだけを対象にしておくことで、ランキングのデータが正しく機能します。
累計 100 PV 以上になったら閲覧数を表示する
カウントは常に行いますが、ページへの表示は累計 100 PV を超えた記事だけにします。
ブログを公開したばかりの時期は、自分がテストで何度か開くだけで数十 PV 溜まります。
「1 PV」や「2 PV」が並んだページを読者に見せても、良い印象にはなりません。
100 PV は「他の人にも実際に読まれた実績がある」と言える最低ラインとして設定しました。
100 PV を超えた瞬間から、ページへの表示が自動的に切り替わります。
しきい値の数字を変えるだけで後から調整できるので、必要に応じて変更してください。
表示するのは累計 PV のみ
取得するデータは「今日・今月・累計」の3種類ですが、ページに表示するのは累計 PV のみにしました。
立ち上げ期に「今日: 1 PV 今月: 3 PV」のような細かい数字を見せても、読者にとってはあまり意味がありません。
今後データが蓄積されてきたタイミングで追加することは簡単にできます。
ファイル構成の全体像
今回作成・変更するファイルは以下の通りです。
~/example-blog/
├── lib/
│ └── db.ts ← 新規作成(SQLite 接続の共通関数)
├── app/
│ ├── api/
│ │ └── views/
│ │ └── route.ts ← 新規作成(閲覧数の記録・取得 API)
│ └── posts/
│ └── [id]/
│ └── page.tsx ← 変更(ViewCounter を追加)
└── components/
└── ViewCounter.tsx ← 新規作成(閲覧数表示コンポーネント)
~/stats.sh ← 新規作成(閲覧数レポートスクリプト)では順番に実装していきます。
STEP 1:lib/db.ts を作成する
なぜ共通関数にするのか
SQLite への接続処理(データベースファイルのパスを指定して接続する)は、API ファイルや将来的に他のファイルでも使います。
毎回同じコードを書くのは非効率ですし、データベースファイルのパスを変更したくなったときに、修正箇所が増えてしまいます。
lib/db.ts という共通ファイルにまとめておくことで、どのファイルからでも getDb() を呼び出すだけで接続できるようになります。
作成手順
VPS に SSH 接続して、以下のコマンドを実行します。
cat > ~/example-blog/lib/db.ts << 'EOF'
import Database from 'better-sqlite3';
import path from 'path';
const DB_PATH = path.join(process.env.HOME || '/home/username', 'example-blog', 'data', 'views.db');
export function getDb(): Database.Database {
return new Database(DB_PATH);
}
EOFコードの説明
import Database from 'better-sqlite3'
前回インストールした better-sqlite3 ライブラリを読み込みます。
Node.js から SQLite を操作するためのすべての機能が、このライブラリに入っています。
import path from 'path'
Node.js に最初から入っているファイルパス操作のライブラリです。
OS によって /(Linux)や \(Windows)などパス区切り文字が異なるため、path.join() を使って安全にパスを組み立てます。
process.env.HOME || '/home/username'
process.env.HOME は OS の環境変数で、ログインユーザーのホームディレクトリのパスが自動で入っています(例:/home/username)。
Linux 環境では通常これで正しく取得できます。|| は「左側が取得できなかった万が一の場合に右側を使う」という意味の予備設定です。
export function getDb()
export をつけることで、他のファイルから import { getDb } from '@/lib/db' という形で呼び出せるようになります。
STEP 2:app/api/views/route.ts を作成する
API Route とは何か
Next.js には「API Route」という機能があります。app/api/ フォルダ以下に route.ts というファイルを置くと、そのファイルが HTTP API のエンドポイント(アクセス先の URL)になります。
例えば app/api/views/route.ts を作ると、https://next.example.com/api/views という URL に対してリクエストを送れるようになります。
静的サイトだった時代は API Route が使えませんでしたが、前回サーバーモードに切り替えたことで使えるようになりました。
これが前回の「サーバーモード移行」が必要だった理由の1つです。
ディレクトリを作成する
mkdir -p ~/example-blog/app/api/viewsmkdir -p は「途中のフォルダも含めてまとめて作成する」コマンドです。-p オプションをつけると、app/api/ が存在しない場合でも一度に作れます。
すでに存在する場合はエラーにならずそのまま続行します。
ファイルを作成する
cat > ~/example-blog/app/api/views/route.ts << 'EOF'
import { NextRequest, NextResponse } from 'next/server';
import { getDb } from '@/lib/db';
export const dynamic = 'force-dynamic';
export async function POST(request: NextRequest) {
try {
const body = await request.json();
const { url } = body;
if (typeof url !== 'string' || url.trim() === '') {
return NextResponse.json({ error: 'Invalid URL' }, { status: 400 });
}
const today = new Date().toISOString().slice(0, 10);
const yearMonth = new Date().toISOString().slice(0, 7);
const db = getDb();
const increment = db.transaction(() => {
db.prepare(`
INSERT INTO daily_views (url, date, count)
VALUES (?, ?, 1)
ON CONFLICT(url, date) DO UPDATE SET count = count + 1
`).run(url, today);
db.prepare(`
INSERT INTO monthly_views (url, year_month, count)
VALUES (?, ?, 1)
ON CONFLICT(url, year_month) DO UPDATE SET count = count + 1
`).run(url, yearMonth);
db.prepare(`
INSERT INTO total_views (url, count)
VALUES (?, 1)
ON CONFLICT(url) DO UPDATE SET count = count + 1
`).run(url);
const cutoff = new Date();
cutoff.setDate(cutoff.getDate() - 60);
const cutoffStr = cutoff.toISOString().slice(0, 10);
db.prepare(`
DELETE FROM daily_views WHERE date < ?
`).run(cutoffStr);
});
increment();
db.close();
return NextResponse.json({ ok: true });
} catch (error) {
console.error('[POST /api/views] Error:', error);
return NextResponse.json({ error: 'Internal Server Error' }, { status: 500 });
}
}
export async function GET(request: NextRequest) {
try {
const { searchParams } = new URL(request.url);
const url = searchParams.get('url');
if (!url) {
return NextResponse.json({ error: 'Missing url parameter' }, { status: 400 });
}
const today = new Date().toISOString().slice(0, 10);
const yearMonth = new Date().toISOString().slice(0, 7);
const db = getDb();
const daily = db.prepare(`
SELECT count FROM daily_views WHERE url = ? AND date = ?
`).get(url, today) as { count: number } | undefined;
const monthly = db.prepare(`
SELECT count FROM monthly_views WHERE url = ? AND year_month = ?
`).get(url, yearMonth) as { count: number } | undefined;
const total = db.prepare(`
SELECT count FROM total_views WHERE url = ?
`).get(url) as { count: number } | undefined;
db.close();
return NextResponse.json({
daily: daily?.count ?? 0,
monthly: monthly?.count ?? 0,
total: total?.count ?? 0,
});
} catch (error) {
console.error('[GET /api/views] Error:', error);
return NextResponse.json({ error: 'Internal Server Error' }, { status: 500 });
}
}
EOFコードの説明
export const dynamic = 'force-dynamic'
Next.js はデフォルトで API のレスポンスをキャッシュすることがあります。
閲覧数カウンターは毎回最新の数字を返す必要があるため、この設定でキャッシュを無効化し、リクエストのたびにサーバーで処理させます。
export async function POST(...) と export async function GET(...)
POST という名前の関数を export すると、POST /api/views へのリクエストをその関数が受け取ります。
同様に GET という名前の関数が GET リクエストを受け取ります。
Next.js の App Router の仕様で、関数名がそのまま HTTP メソッドに対応します。
new Date().toISOString().slice(0, 10)
現在時刻を "2026-04-29T07:30:00.000Z" のような形式に変換し、.slice(0, 10) で先頭10文字だけ取り出して、"2026-04-29" という日付文字列を作ります。
INSERT INTO ... ON CONFLICT(...) DO UPDATE SET count = count + 1
「UPSERT(アップサート)」と呼ばれる SQL の書き方です。
「レコードがなければ新規作成、あれば更新」を1つの文で実行できます。
- 初めてアクセスされた記事:
count = 1で新規レコードを作成 - 2回目以降のアクセス:既存レコードの
countを +1
?(プレースホルダー)とプリペアドステートメント
SQL 文の中に直接値を書かずに ? という記号を使い、.run(url, today) のように後から値を渡す書き方です。
「プリペアドステートメント」と呼ばれるセキュリティ対策で、SQL インジェクション攻撃(悪意のある SQL 文を混入させる攻撃)を防ぎます。
URL などの外部から受け取ったデータを SQL に使うときは必須の対策です。
db.transaction(() => { ... })
トランザクションとは「複数の処理をひとまとまりとして扱う仕組み」です。
3つのテーブル(daily_views・monthly_views・total_views)への書き込みは、必ず全部成功するか、全部失敗するかのどちらかになります。
例えばネットワークエラーで途中で処理が止まったとき、daily_views だけ +1 されて total_views は更新されないという「カウントのズレ」が発生するのを防ぎます。
daily_views の古いデータを自動削除する
トランザクションの中に、60日より古い daily_views のレコードを削除する処理を入れています。
アクセスのたびに実行される処理なので、定期タスク(cron ジョブなど)を別途設定しなくても自動的に古いデータが削除されます。
60日という数字は「過去30日間のランキング計算(将来実装予定)に必要な最低限の期間(30日)+余裕分(30日)」として設定しました。
daily?.count ?? 0
daily は「値があるかもしれないし、ないかもしれない」という型になっています。
?.:dailyが存在する場合だけ.countを参照する(オプショナルチェイニング)?? 0:nullまたはundefinedだった場合は0にする(Nullish 合体演算子)
記事に初めてアクセスした直後などまだレコードが存在しない場合でも、エラーにならず 0 を返してくれます。
STEP 3:components/ViewCounter.tsx を作成する
このコンポーネントの役割
記事ページに組み込むコンポーネントです。
ページが表示されたときに自動で以下の2つを実行します。
/api/viewsに POST リクエストを送り、閲覧数を +1 する/api/viewsに GET リクエストを送り、最新の閲覧数を取得して表示する
なぜ 'use client' が必要なのか
ファイルの先頭に 'use client' と書くと、そのコンポーネントはブラウザ側で実行されるクライアントコンポーネントになります。
閲覧数のカウントは「ページが実際にブラウザで表示されたとき」に行いたいです。
サーバーサイドで実行してしまうと、ビルドのたびにカウントされてしまう問題が起きます。
「ページが表示されたタイミングで処理を実行する」機能(useEffect フック)はクライアントコンポーネントでしか使えないため、'use client' が必要になります。
作成手順
cat > ~/example-blog/components/ViewCounter.tsx << 'EOF'
'use client';
import { useEffect, useState } from 'react';
type ViewData = {
daily: number;
monthly: number;
total: number;
};
type Props = {
path: string;
};
export default function ViewCounter({ path }: Props) {
const [views, setViews] = useState<ViewData | null>(null);
useEffect(() => {
async function recordAndFetch() {
try {
await fetch('/api/views', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ url: path }),
});
const res = await fetch(`/api/views?url=${encodeURIComponent(path)}`);
const data: ViewData = await res.json();
setViews(data);
} catch (err) {
console.error('[ViewCounter] Error:', err);
}
}
recordAndFetch();
}, [path]);
if (!views) return null;
if (views.total < 100) return null;
return (
<div className="text-sm text-gray-400">
累計: {views.total.toLocaleString()} PV
</div>
);
}
EOFコードの説明
useState<ViewData | null>(null)
useState は React のフックで、コンポーネント内で変化する値(状態)を管理します。
初期値は null(データ未取得状態)で、API からデータが返ってきたら setViews(data) で値を更新します。
値が変わると画面が自動的に再描画されます。
useEffect(() => { ... }, [path])
コンポーネントがブラウザに表示されたタイミングで処理を実行するフックです。
第2引数の [path] は「path の値が変わったときに再実行する」という依存配列です。
記事ページでは path は変わらないため、実質的にページ表示時に1回だけ実行されます。
encodeURIComponent(path)
URL のクエリパラメーターに /posts/sample-article のようなスラッシュを含む文字列を渡すと、URL の構造が壊れてしまいます。encodeURIComponent() で / → %2F のように変換することで安全に渡せます。
if (!views) return null
API のレスポンスが返ってくる前は何も表示しません。
「読み込み中…」を表示することも考えましたが、一瞬表示されてから消えるちらつきが気になったため、null を返すシンプルな実装にしました。
if (views.total < 100) return null
累計 PV が 100 未満のときは何も表示しません。
カウントは常に行われていますが、表示だけを制御しています。
100 PV を超えた瞬間から自動で表示が切り替わります。
views.total.toLocaleString()
数値を読みやすい文字列に変換します。
例えば 1204 が 1,204 のようにカンマ区切りで表示されます。
STEP 4:個別記事ページに閲覧数を追加する
app/posts/[id]/page.tsx に以下の2か所を変更します。
import 文の最終行番号を確認する
まず、現在のファイルで import 文が何行目で終わっているかを確認します。
grep -n "^import" ~/example-blog/app/posts/\[id\]/page.tsx | tail -5grep -n は「行番号つきで検索する」コマンドです。^import は「行の先頭が import で始まる行」を意味します。tail -5 は「最後の5行だけ表示する」オプションです。
出力例:
3:import rehypeRaw from 'rehype-raw';
4:import Image from 'next/image';
5:import Link from 'next/link';
6:import type { Metadata } from 'next';
7:import { CodeBlock } from '../../../components/CodeBlock';この場合、import の最終行は7行目です。
import 文を追加する
確認した最終行番号(例:7行目)の後に ViewCounter の import を追加します。
sed -i '7a import ViewCounter from '"'"'../../../components/ViewCounter'"'"';' ~/example-blog/app/posts/\[id\]/page.tsxコマンドの説明
sed -i:ファイルを直接編集する(-iは「in-place」の略で「その場で書き換える」という意味)'7a ...':7行目の後にテキストを追加する(aは append=追加の意味)
7 の部分はご自身の環境で確認した行番号に変更してください。
ViewCounter を配置する行番号を確認する
次に、アイキャッチ画像コメントが何行目にあるかを確認します。
grep -n "アイキャッチ画像" ~/example-blog/app/posts/\[id\]/page.tsx出力例:
144: {/* — アイキャッチ画像 */}この場合、144行目の直前(143行目の後)に ViewCounter を挿入します。
JSX に ViewCounter を配置する
確認した行番号の1つ前(例:143)を使って以下を実行します。
sed -i '143a\ {/* — 閲覧数カウンター */}\
<div className="px-6 pb-4">\
<ViewCounter path={`/posts/${postData.id}`} />\
</div>' ~/example-blog/app/posts/\[id\]/page.tsxpath={/posts/${postData.id}} について
postData.id は Markdown ファイルのスラッグです(例:sample-article)。
テンプレートリテラルを使って /posts/sample-article という形の URL パスを生成し、ViewCounter に渡しています。
実際のページでは、記事ごとのスラッグが自動で入ります。
挿入後の構造はこのようになります。
メタ情報エリア(日付・ステータス・タグ)
↓
閲覧数カウンター(ViewCounter) ← ここに挿入
↓
アイキャッチ画像
↓
記事本文STEP 5:ビルドしてデプロイする
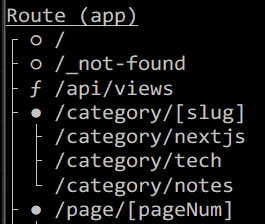
cd ~/example-blog && npm run build && pm2 restart example-blogビルド完了後のルート一覧に /api/views が f (Dynamic) として表示されていれば成功です。f は「force-dynamic」を意味し、API が正しくサーバー側で処理されることを示しています。
STEP 6:API の動作をテストする
デプロイ後、VPS 上で直接 API をテストします。
POST テスト(閲覧数の記録)
curl -s -X POST http://localhost:3000/api/views \
-H "Content-Type: application/json" \
-d '{"url":"/posts/test"}' | python3 -m json.toolコマンドの説明
curl は URL に対してリクエストを送るコマンドです。ブラウザの代わりにターミナルから HTTP 通信ができます。
-s:進行状況のメッセージを非表示にする(silent モード)-X POST:HTTP メソッドを POST に指定する-H "Content-Type: application/json":送るデータの形式が JSON であることをサーバーに伝えるヘッダー-d '{"url":"/posts/test"}':送信するデータ本体(/posts/testという URL を閲覧したことを伝える)| python3 -m json.tool:返ってきた JSON を読みやすく整形して表示する
{"ok": true} が返ってくれば成功です。
GET テスト(閲覧数の取得)
curl -s "http://localhost:3000/api/views?url=%2Fposts%2Ftest" | python3 -m json.toolURL の中の %2F は / のパーセントエンコーディングです。/posts/test を URL パラメーターとして安全に渡すための変換形式です。
{"daily": 1, "monthly": 1, "total": 1} が返ってくれば成功です。
データベースの確認
sqlite3 ~/example-blog/data/views.db "SELECT * FROM total_views;"/posts/test|1 が表示されれば、SQLite に正しく記録されています。
テストデータを削除する
テスト用に作ったデータは不要なので削除しておきます。
sqlite3 ~/example-blog/data/views.db "DELETE FROM daily_views WHERE url = '/posts/test';"
sqlite3 ~/example-blog/data/views.db "DELETE FROM monthly_views WHERE url = '/posts/test';"
sqlite3 ~/example-blog/data/views.db "DELETE FROM total_views WHERE url = '/posts/test';"STEP 7:閲覧数レポートスクリプト(stats.sh)を作成する
なぜスクリプトが必要なのか
記事ページに閲覧数を表示するようにしましたが、累計 100 PV 未満は非表示にしています。
立ち上げ期は、実際にどの記事が何回読まれているかをブラウザで確認できません。
また、毎回 SSH 接続して sqlite3 コマンドを直接打つのは面倒です。
スクリプト1つで整形されたレポートを確認・出力できるようにします。
管理画面ページ(例:/admin/views)を Next.js に作ることも考えましたが、Googlebot がそのページを閲覧する可能性や、意味のないページを増やす問題があります。
SSH + WinSCP の組み合わせの方がシンプルで安全です。
スクリプトを作成する
cat > ~/stats.sh << 'EOF'
#!/bin/bash
# =============================================
# stats.sh - 閲覧数レポート出力スクリプト
# 使い方:
# ~/stats.sh → ターミナルに表示
# ~/stats.sh --csv → CSV ファイルに出力
# ~/stats.sh --md → Markdown ファイルに出力
# =============================================
DB="$HOME/example-blog/data/views.db"
POSTS_DIR="$HOME/example-blog/posts"
DATE=$(date +%Y-%m-%d)
YEARMONTH=$(date +%Y-%m)
get_title() {
local url="$1"
local slug="${url#/posts/}"
if [[ "$url" != /posts/* ]]; then
echo "$url"
return
fi
local mdfile="$POSTS_DIR/${slug}.md"
if [ -f "$mdfile" ]; then
local title
title=$(grep -m1 '^title:' "$mdfile" | sed 's/^title:[[:space:]]*//' | tr -d '"'"'")
if [ -n "$title" ]; then
echo "$title"
return
fi
fi
echo "$url"
}
format_terminal() {
while IFS='|' read -r url count; do
local title
title=$(get_title "$url")
printf "%-45s %-6s PV\n" "$title" "$count"
done
}
format_csv() {
local kind="$1"
local period="$2"
while IFS='|' read -r url count; do
local title
title=$(get_title "$url")
echo "${kind},\"${title}\",${url},${count},${period}"
done
}
format_md() {
while IFS='|' read -r url count; do
local title
title=$(get_title "$url")
echo "| ${title} | ${url} | ${count} |"
done
}
if [ $# -eq 0 ]; then
echo ""
echo "=== 累計PVランキング ==="
sqlite3 "$DB" \
"SELECT url, count FROM total_views ORDER BY count DESC;" \
| format_terminal
echo ""
echo "=== 今月(${YEARMONTH})PVランキング ==="
sqlite3 "$DB" \
"SELECT url, count FROM monthly_views WHERE year_month='${YEARMONTH}' ORDER BY count DESC;" \
| format_terminal
echo ""
echo "=== 今日(${DATE})PVランキング ==="
sqlite3 "$DB" \
"SELECT url, count FROM daily_views WHERE date='${DATE}' ORDER BY count DESC;" \
| format_terminal
echo ""
elif [ "$1" = "--csv" ]; then
OUTFILE="$HOME/views_${DATE}.csv"
{
echo "種別,タイトル,URL,PV,集計期間"
sqlite3 "$DB" \
"SELECT url, count FROM total_views ORDER BY count DESC;" \
| format_csv "累計" "全期間"
sqlite3 "$DB" \
"SELECT url, count FROM monthly_views WHERE year_month='${YEARMONTH}' ORDER BY count DESC;" \
| format_csv "今月" "${YEARMONTH}"
sqlite3 "$DB" \
"SELECT url, count FROM daily_views WHERE date='${DATE}' ORDER BY count DESC;" \
| format_csv "今日" "${DATE}"
} > "$OUTFILE"
echo "CSVファイルを出力しました: $OUTFILE"
elif [ "$1" = "--md" ]; then
OUTFILE="$HOME/views_${DATE}.md"
{
echo "# 閲覧数レポート ${DATE}"
echo ""
echo "## 累計PVランキング"
echo ""
echo "| タイトル | URL | PV |"
echo "|---------|-----|-----|"
sqlite3 "$DB" \
"SELECT url, count FROM total_views ORDER BY count DESC;" \
| format_md
echo ""
echo "## 今月(${YEARMONTH})PVランキング"
echo ""
echo "| タイトル | URL | PV |"
echo "|---------|-----|-----|"
sqlite3 "$DB" \
"SELECT url, count FROM monthly_views WHERE year_month='${YEARMONTH}' ORDER BY count DESC;" \
| format_md
echo ""
echo "## 今日(${DATE})PVランキング"
echo ""
echo "| タイトル | URL | PV |"
echo "|---------|-----|-----|"
sqlite3 "$DB" \
"SELECT url, count FROM daily_views WHERE date='${DATE}' ORDER BY count DESC;" \
| format_md
} > "$OUTFILE"
echo "Markdownファイルを出力しました: $OUTFILE"
else
echo "使い方: ~/stats.sh [--csv | --md]"
exit 1
fi
EOFスクリプトが作成できたら、実行できるように権限を付与します。
chmod +x ~/stats.shexample-blog の部分はご自身の作業ディレクトリ名に置き換えてください。
最後の chmod +x ~/stats.sh は「このファイルを実行可能にする」コマンドです。
Linux では新しく作ったファイルはデフォルトで実行できない状態になっているため、この1行で「実行していいですよ」という権限を付与します。
スクリプトの主要コードの説明
get_title() 関数
URL(例:/posts/sample-article)からスラッグを取り出し、対応する Markdown ファイルのフロントマターから title: を読み取る関数です。
/posts/sample-article
→ スラッグを取り出す → sample-article
→ .md を付けてパスを組み立てる → ~/example-blog/posts/sample-article.md
→ grep で title: の行を読む → 記事の日本語タイトルデータベースにタイトルを保存する方法も検討しましたが、記事タイトルを変更したときに DB 側が古いままになるリスクがあります。
Markdown ファイルを直接読む方が、常に最新のタイトルを取得できます。
${url#/posts/}
Bash のパラメーター展開という書き方です。# の後に書いたパターンを変数の先頭から取り除きます。/posts/sample-article から /posts/ を取り除いて sample-article だけにします。
IFS='|' read -r url count
IFS は「フィールド区切り文字」の設定です。
SQLite の出力は url|count という形式(パイプ区切り)なので、| で分割して url と count の2つの変数に入れます。
{ ... } > "$OUTFILE"
波括弧で囲まれた複数のコマンドの出力をまとめて1つのファイルに書き出す構文です。
ヘッダー行から各テーブルのデータまで、すべてを1つのファイルに保存します。
スクリプトの使い方
ターミナルで確認したいとき
~/stats.shCSV ファイルを出力したいとき
~/stats.sh --csvMarkdown ファイルを出力したいとき
~/stats.sh --md出力ファイルはホームディレクトリ(~/)に日付入りのファイル名で保存されます。
~/views_2026-04-29.csv
~/views_2026-04-29.mdWinSCP で VPS に接続してホームディレクトリを開くと、これらのファイルが表示されます。
ダウンロードすれば、手元の PC でいつでも確認できます。
同じ日に複数回実行すると上書きされます。
まとめ
今回実装した閲覧数カウンターは、Google アナリティクスとは役割が違います。
GA4 は訪問者の行動・流入元・デバイスなどを詳細に分析するツールです。
独自カウンターは、サイト内でのランキング表示や、記事ページへの閲覧数表示に使います。
両方を持つことで、データを自分で活用できる範囲が広がります。
ゼロから作ったシステムなのでデータは完全に自分のものであり、自由に使うことができることが、何より気に入っています。
今回実装した内容を整理します。
| ファイル | 内容 |
|---|---|
lib/db.ts | SQLite 接続の共通関数 |
app/api/views/route.ts | POST(記録)・GET(取得)API |
components/ViewCounter.tsx | 累計 100 PV 以上で「累計: ○○ PV」を表示 |
app/posts/[id]/page.tsx | ViewCounter を記事ページに追加 |
~/stats.sh | 閲覧数レポートをターミナル・CSV・Markdown で出力 |
次の回(第20回)では、蓄積した閲覧数データを使って「全期間人気記事ランキング」をサイドバーに表示する実装を行います。
▼ この回で採用しなかった選択肢との比較検討を、別サイトにまとめています。
次回の記事はこちらです。