
これまでの Next.js ブログサイト構築シリーズをまとめたページは以下の通りです。

第15回で Google Search Console を設定してから、しばらく経ったある日のことです。

Search Console のレポートを確認していると、
「インデックスに登録されないページ」という項目に1件の URL が表示されていました。
https://next.lifework-blog.com/page/2トップページのページネーション、つまり「2ページ目」の URL です。
「これは修正が必要なのか、それとも放置していいのか。」
調べてみると、これは対応が必要な問題であることがわかりました。
今回の補足記事では、この指摘への対処方法を解説します。
Search Console が「インデックスに登録されないページ」を報告するとは
Google Search Console には、Google がサイトをクロールした結果を教えてくれる「ページのインデックス登録」というレポートがあります。
このレポートには、インデックス登録されているページだけでなく、「クロールはしたがインデックスには登録しなかったページ」の一覧も表示されます。
今回報告されたのは「重複しています、正規ページがユーザーによって指定されています」または「クロール済み – インデックス未登録」に分類されるケースです。
Google がページをクロールして中身を確認したものの、「このページは検索結果に出す必要がなさそうだ」と判断した、ということを意味しています。
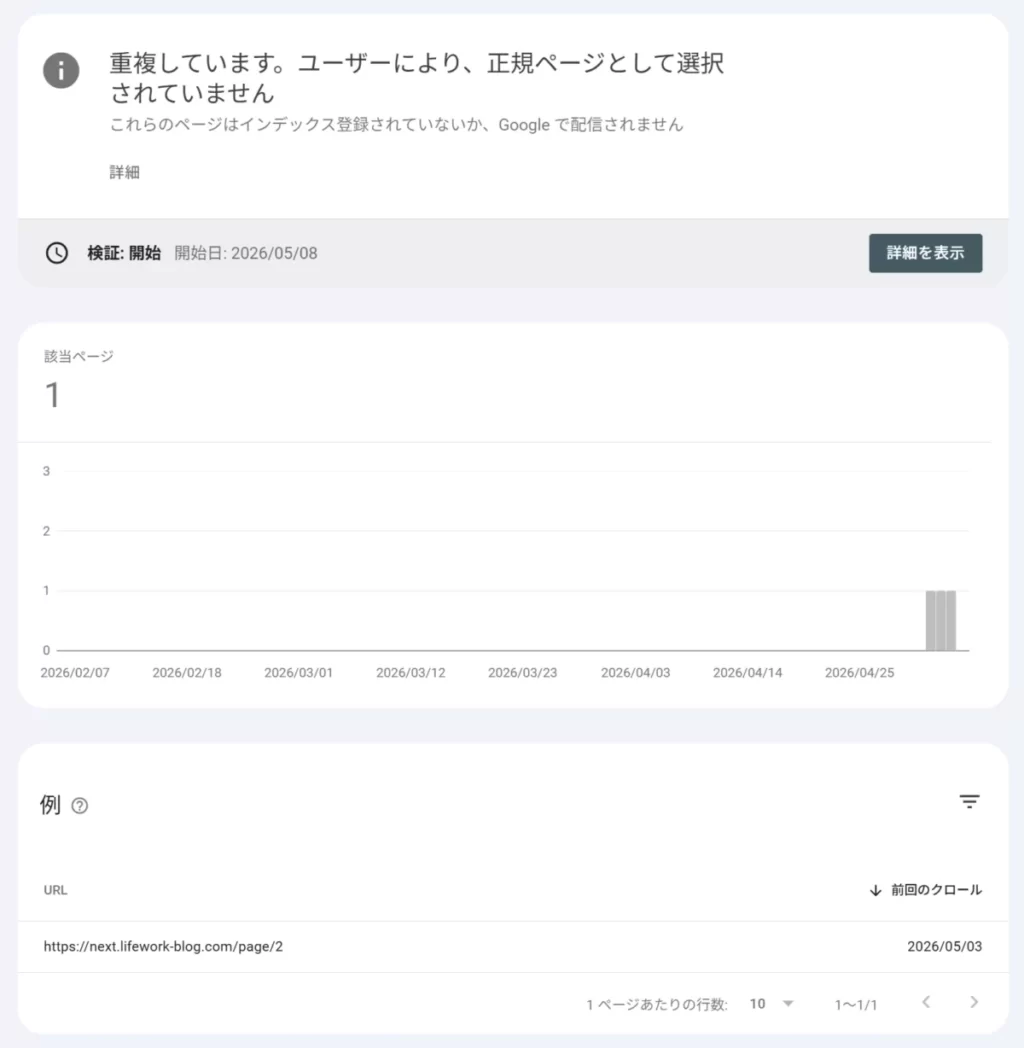
Google Search Console の「インデックスに登録されないページ」に、サイトのトップページの2ページ目が、「重複しています。ユーザーにより、正規ページとして選択されていません」となっています。
なぜページネーションは noindex にすべきなのか
/page/2 のようなページネーションページには、以下の特徴があります。
- 「ブログの2ページ目」を Google で検索するユーザーはいない
- 記事カードが並んでいるだけで、そのページ固有のコンテンツがない
- 各記事の本体はすでに
/posts/記事スラッグという URL で個別にインデックスされている
このため、SEO の世界では「ページネーションの2ページ目以降は noindex にする」のが現在の標準的な対処法です。
WordPress の Yoast SEO プラグインも、デフォルトでこの設定を採用しています。
noindex を設定しないまま放置すると、Google が /page/2 をクロールするためのリソースを使い続け、本来インデックスしてほしい個別記事のクロールが後回しになる可能性があります。
Search Console が指摘してくれたことで、きちんと対応する機会をもらえたと前向きに捉えました。
Search Console を設定しておくと、こうしたサイトのエラーを気づくきっかけにもなるので助かります。
noindex とは何か
noindex は、検索エンジンに「このページを検索結果に表示しないでほしい」と伝えるための設定です。
以下のような <meta> タグを HTML の <head> の中に記述することで機能します。
<meta name="robots" content="noindex, follow" />robots メタタグに指定できる主な値は以下の通りです。
| 値 | 意味 |
|---|---|
noindex | このページを検索結果に表示しない |
index | このページを検索結果に表示してよい(デフォルト) |
follow | このページ内のリンクをたどってよい(デフォルト) |
nofollow | このページ内のリンクをたどらないでほしい |
今回は noindex, follow の組み合わせを設定します。
follow を維持する理由は、ページネーションページには各記事へのリンクが並んでいるためです。nofollow にしてしまうと、それらのリンクも Google に無視されてしまいます。
「このページ自体は検索結果に出さなくていいが、ページ内のリンクはたどってほしい」という意図を伝えるために、follow は残しておきます。
実装:generateMetadata 関数を追加する
Next.js では、generateMetadata という特別な関数をページファイルに書くと、ビルド時に自動で <head> タグの内容を生成してくれます。
今回変更するファイルは1つだけです。
| ファイル | 変更内容 |
|---|---|
app/page/[pageNum]/page.tsx | generateMetadata 関数を追加 |
ファイルを開く
code ~/example-blog/app/page/\[pageNum\]/page.tsxgenerateMetadata 関数を追加する
ファイルの中にある generateStaticParams 関数の閉じカッコ(})の直後に、以下のコードを追加します。
export async function generateMetadata({
params,
}: {
params: Promise<{ pageNum: string }>;
}) {
const { pageNum } = await params;
return {
title: `新着記事 - ページ ${pageNum}`,
robots: {
index: false, // このページ自体はインデックスしない(noindex)
follow: true, // ページ内のリンク(各記事)はたどってよい(follow)
},
};
}各コードの意味
export async function generateMetadata
generateMetadata は Next.js が特別に認識する関数名です。
この名前で関数を書くと、Next.js がビルド時に自動でその内容を <head> タグに書き出してくれます。export は「この関数を外部から使えるようにする」という宣言です。
params: Promise<{ pageNum: string }>
URL の動的な部分(/page/2 の 2 の部分)を受け取るための引数です。await params で実際の値(文字列 "2" など)を取り出しています。
title: \新着記事 – ページ ${pageNum}“
バックティック(`)で囲んだ文字列は「テンプレートリテラル」と呼ばれ、${変数名} の形で変数の値を埋め込めます。layout.tsx に設定されているタイトルテンプレートが自動でサイト名を補完するため、最終的なタイトルは「新着記事 – ページ 2 | あなたのブログ名」のような形になります。
robots: { index: false, follow: true }
Next.js がこの設定を読み取り、以下の <meta> タグを自動生成します。
<meta name="robots" content="noindex, follow" />index: false が noindex、follow: true が follow に対応しています。
ビルドとデプロイを実行する
cd ~/example-blog && npm run build./deploy.sh動作確認
デプロイ完了後、ブラウザで /page/2 を開きます。
F12 キーで開発者ツールを開き、「Elements」タブを選択します。Ctrl + F で検索欄を開いて robots と入力してください。
以下のタグが <head> の中に存在すれば設定は正しく反映されています。
<meta name="robots" content="noindex, follow"/>あわせて <title> タグも確認します。
<title>新着記事 - ページ 2 | あなたのブログ名</title>サイト名が1回だけ表示されていれば完了です。
Search Console に修正を通知する
今回のコード修正とデプロイにより、サーバー側の対応は完了しています。
次は Search Console 側に「修正が完了した」ことを伝える操作が必要です。
Search Console のレポートで該当の問題を開き、「修正を検証」ボタンをクリックしてください。
これにより、Google が対象ページを再クロールするスケジュールが組まれます。
検証には数日かかることがありますが、処理が完了すると Search Console からメールで通知が届きます。
「修正を検証」ボタンを押さなくても、Google が自然にクロールしたタイミングでレポートは更新されますが、ボタンを押すことで再クロールが早めにスケジューリングされるため、押しておくことをおすすめします。
検証を開始すると、Search Console から上記のようなメールが届きます。
まとめ
今回は、Google Search Console が検出したページネーションページへの noindex 対応を解説しました。
作業内容を整理すると、以下の通りです。
| 項目 | 内容 |
|---|---|
| 変更ファイル | app/page/[pageNum]/page.tsx |
| 追加した関数 | generateMetadata |
| 設定内容 | robots: { index: false, follow: true } |
| 生成されるタグ | <meta name="robots" content="noindex, follow"> |
変更するファイルは1つ、追加するコードも数行だけの小さな作業です。
しかし、Search Console が教えてくれたことに素直に対応しておくことで、Google が個別記事のクロールに集中できる環境が整います。
Search Console は設定して終わりではなく、定期的にレポートを確認することで、こうした改善のヒントを継続的に得られるツールです。
第15回で設定した後は、ぜひ定期的に確認する習慣をつけてみてください。
▼ この回の手順には書かなかった話を、別サイトにまとめています。

次回の記事はこちらです。


